| Version 49 (modified by , 13 days ago) ( diff ) |
|---|
Нормализација на базата и индекси
1. Почетна релација (UNF)
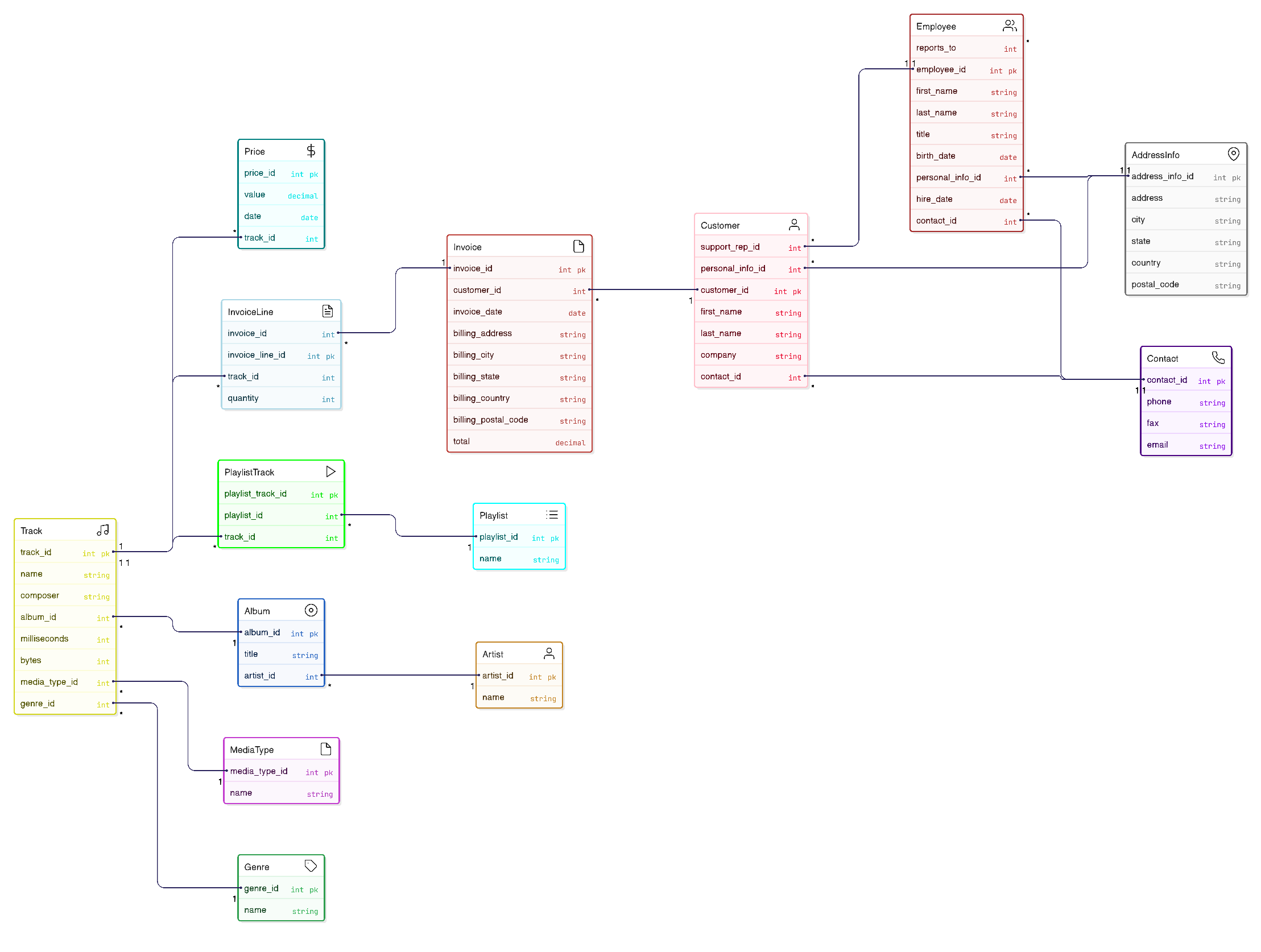
BaseRelation(track_id, name, album_id, artist_id, media_type_id, genre_id, composer, milliseconds, bytes, price_id, value, date, invoice_line_id, invoice_id, quantity, customer_id, first_name, last_name, company, support_rep_id, personal_info_id, contact_id, employee_id, title, reports_to, birth_date, hire_date, address_info_id, address, city, state, country, postal_code, phone, fax, email, playlist_id, playlist_name, playlist_track_id)
2. Функционални зависности (FDs)
Track
track_id → name, album_id, media_type_id, genre_id, composer, milliseconds, bytes
Price
price_id → value, date, track_id
Album
album_id → artist_id
InvoiceLine
invoice_line_id → invoice_id, track_id, quantity
Invoice
invoice_id → customer_id
Customer
customer_id → first_name, last_name, company, support_rep_id, personal_info_id, contact_id
Employee
employee_id → title, reports_to, birth_date, hire_date
PersonalInfo
personal_info_id → address, city, state, country, postal_code, phone, fax, email
Playlist
playlist_id → playlist_name
PlaylistTrack
playlist_track_id → playlist_id, track_id
3. Прва нормална форма (1NF)
Сите атрибути се атомични → релацијата е во 1NF.
Примарен клуч (на BaseRelation):
(invoice_line_id, playlist_track_id)→ (track_id, name, album_id, artist_id, media_type_id, genre_id, composer, milliseconds, bytes, price_id, value, date invoice_id, quantity, customer_id, first_name, last_name, company, support_rep_id, personal_info_id, contact_id, employee_id, title, reports_to, birth_date, hire_date, address_info_id, address, city, state, country, postal_code, phone, fax, email, playlist_id, playlist_name)
(секој ред е уникатен по комбинацијата на фактурна линија и песна во плејлиста).
(invoice_line_id, playlist_track_id)
4. Втора нормална форма (2NF)
Ги одвојуваме зависностите од делови на составениот клуч:
4.1 Track
Track(track_id, name, album_id, media_type_id, genre_id, composer, milliseconds, bytes) PK: track_id
4.2 Price
Price(price_id, value, date, track_id) PK: price_id FK: track_id → Track(track_id)
4.3 Album
Album(album_id, artist_id) PK: album_id FK: artist_id → Artist(artist_id)
4.4 Artist
Artist(artist_id, artist_name) PK: artist_id
4.5 InvoiceLine
InvoiceLine(invoice_line_id, invoice_id, track_id, quantity) PK: invoice_line_id FK: invoice_id → Invoice(invoice_id) FK: track_id → Track(track_id)
4.6 Invoice
Invoice(invoice_id, customer_id) PK: invoice_id FK: customer_id → Customer(customer_id)
4.7 Customer
Customer(customer_id, first_name, last_name, company, support_rep_id, personal_info_id, contact_id) PK: customer_id FK: support_rep_id → Employee(employee_id)
4.8 Employee
Employee(employee_id, title, reports_to, birth_date, hire_date) PK: employee_id
4.9 PersonalInfo
PersonalInfo(personal_info_id, address, city, state, country, postal_code, phone, fax, email) PK: personal_info_id
4.10 Playlist
Playlist(playlist_id, playlist_name) PK: playlist_id
4.11 PlaylistTrack
PlaylistTrack(playlist_track_id, playlist_id, track_id) PK: playlist_track_id FK: playlist_id → Playlist(playlist_id) FK: track_id → Track(track_id)
4.12 MediaType
MediaType(name, media_type_id) PK: media_type_id
4.13 !Genre
MediaType(name, genre_id) PK: genre_id
5. Трета нормална форма (3NF)
album_id → artist_id → Artist е одвоен.
support_rep_id → Employee е FK, нема транзитивна зависност во Customer.
Адресата е изнесена во PersonalInfo.
Сите не-клучни атрибути зависат директно од клучевите.
Сите релации се во 3NF.
Финален нормализиран модел (3NF)
Сите релации на овјо начин се сведени во 3NF, дополнително да отстраниме редундантост, ќе издвоиме една релации во две. За да се постигне највисоката нормализирана состојба на базата BNF.
- Бидејќи PersonalInfo содржи информации за адреса на живеење и контакт, може да го издвоиме во два ентитети AddressInfo и Contact (може да се случо двајца customers/employees да живеат на иста адреса, а да имаат различно инфо за котакт, во тој случај би чувале потполно исти податоци за адреса кај двајцата, на овој начин еден запис од AdressInfo можеме да го искористиме за две личности).
Track(track_id, name, album_id, media_type_id, genre_id, composer, milliseconds, bytes)
MediaType(media_type_id, name)
Genre(genre_id, name)
Price(price_id, value, date, track_id)
Album(album_id, artist_id, title)
Artist(artist_id, artist_name)
InvoiceLine(invoice_line_id, invoice_id, track_id, quantity)
Invoice(invoice_id, customer_id)
Customer(customer_id, first_name, last_name, company, support_rep_id, personal_info_id, contact_id)
Employee(employee_id, title, reports_to, birth_date, hire_date)
AddressInfo(address_info_id, address, city, state, country, postal_code)
Contact(contact_id, phone, fax, email)
Playlist(playlist_id, playlist_name)
PlaylistTrack(playlist_track_id, playlist_id, track_id)
*Забелешка: во некои релации имам оставено сурогат клучеви за полесно користење на податоците во веб апликациијата, кои би можеле да се исфрлат, на тој начин релацијата би имала композитни примарни клучеви).
Релациона алгебра за прашалникот: Најпопуларен артист по жанр за корисник
1. PlayCounts
Се пресметува бројот на плеј-стани за секој жанр и уметник за одреден клиент (со ID 123). Операциите што се користат се:
- Join: Поврзување на сите потребни табли (customer, invoice, invoice_line, track, genre, album, artist) со операцијата
⋈. - Selection (σ): Применуваме услов за селектирање само на податоци за клиент со ID 123.
- Grouping (γ): Групираме по жанр и уметник и пресметуваме бројот на плеј-стани за секој пар жанр-уметник со функцијата COUNT.
Релационата алгебра за PlayCounts:
PlayCounts = γ_{g.genre_id, g.name → genre_name, ar.name → artist_name, COUNT(*) → play_count} (σ_{c.customer_id = 123}((customer ⋈ invoice) ⋈ (invoice_line ⋈ track) ⋈ (track ⋈ genre) ⋈ (track ⋈ album) ⋈ (album ⋈ artist)))
2. MaxPlayCounts
Се пресметува максималниот број на плеј-стани за секој жанр. Операциите што се користат се:
- Grouping (γ): Групирање по
genre_idи пресметување на максималниот број на плеј-стани за секој жанр користејќи ја функцијатаMAX.
Релационата алгебра за MaxPlayCounts:
MaxPlayCounts = γ_{genre_id, MAX(play_count) → max_count} (PlayCounts)
3. FinalResult
Се прави Join помеѓу PlayCounts и MaxPlayCounts, за да се изберат само оние редови каде што бројот на плеј-стани се совпаѓа со максималниот број за даден жанр. Се избираат само атрибутите genre_name, artist_name, и play_count.
Релационата алгебра за финалниот резултат:
FinalResult = π_{pc.genre_name, pc.artist_name, pc.play_count} (PlayCounts ⋈_{pc.genre_id = mpc.genre_id ∧ pc.play_count = mpc.max_count} MaxPlayCounts)
Целосен израз на релационата алгебра
Со комбинирање на сите чекори, добиваме целосен израз за релационата алгебра:
π_{pc.genre_name, pc.artist_name, pc.play_count} ((γ_{g.genre_id, g.name → genre_name, ar.name → artist_name, COUNT(*) → play_count}(σ_{c.customer_id = 123} ((customer ⋈ invoice) ⋈ (invoice_line ⋈ track) ⋈ (track ⋈ genre) ⋈ (track ⋈ album) ⋈ (album ⋈ artist)))) ⋈{pc.genre_id = mpc.genre_id ∧ pc.play_count = mpc.max_count} (γ{genre_id, MAX(play_count) → max_count} (PlayCounts)))
Индекси
За поефикасно извршување на прашалникот „Најпопуларен артист по жанр за корисник“ ги креираме следните индекси:
- invoice(customer_id): Овој индекс е неопходен за брзо спојување (JOIN) на табелите customer и invoice.
- invoice_line(invoice_id): Овој индекс го забрзува спојувањето на табелите invoice и invoice_line.
- track(genre_id): Овој индекс е клучен за ефикасно спојување на табелите track и genre.
- track(album_id): Овој индекс е важен за спојувањето на табелите track и album.
- album(artist_id): Овој индекс е потребен за брзо спојување на табелите album и artist.
- genre(genre_id, name): композитен индек - овој индекс ќе ѝ помогне на базата на податоци да го оптимизира делот од барањето што се однесува на GROUP BY. Дополнително, ќе помогне и во спојувањето на табелите track и genre бидејќи го содржи genre_id.
- artist(artist_id, name): композитен индекс - слично на претходниот, овој индекс ќе ја подобри ефикасноста на GROUP BY операцијата и ќе помогне во спојувањето на табелите album и artist.
- (g.genre_id, g.name, ar.name): композитен индекс: овој индекс е специјално дизајниран да ја оптимизира GROUP BY операцијата со тоа што ги содржи сите колони по кои се врши групирањето. Со тоа, базата на податоци избегнува скапо сортирање на податоците и може брзо да ги изврши пресметките, што значи побрзо време на одговор.
Explain plan
Резултати од двете извршувањаа на Explain Plan (со и без индекси)
Структура на планот
- Користи CTE playcounts → HashAggregate → Hash Join (track → genre) → Nested Loops за invoice → invoice_line → track → album → artist.
- Потоа се пресметува Max Play Counts и се join-ира со playcounts.
- Финално се враќаат редовите.
- Физичките операции се исти во двата плана.
| Клучни метрики | Прв план | Втор план |
| Hash Join (финален) | 0.254–0.258 ms | 0.249–0.254 ms |
| Време на извршување | 0.372 ms | 0.345 ms |
| Време на планирање | 3.223 ms | 0.858 ms |
| Buffers (shared hit) | 223 | 223 |
| Врати редови | 8 | 8 |
Заклучко: Извршувањето е малку побрзо кај вториот план, а најголема разлика е во времето за планирање. Бидејќи станува збор за помала база на податоци разликата на извршувањето не е значајна, меѓуто времето на планирање е намалено на 1/4 од она без индекси.
Attachments (3)
- Fianl Diagram Light.png (193.1 KB ) - added by 5 weeks ago.
- explain_plan.txt (10.5 KB ) - added by 13 days ago.
- explain_plan2.txt (10.4 KB ) - added by 8 days ago.
{kind=link}
{kind=link}
Download all attachments as: .zip