| Version 46 (modified by , 7 weeks ago) ( diff ) |
|---|
Напредна тема
Зошто се одлучивме за темата Партиционирање ?
Во овој проект се одлучивме да примениме партиционирање на табели (table partitioning) со цел да се подобрат перформансите, скалабилноста и одржливоста на базата на податоци. Системот претставува железничка платформа каде што се генерира голем обем на податоци, особено за патувања, билети и плаќања, кои со тек на време значително се зголемуваат. Поради тоа, класичен пристап со една голема табела би довел до намалени перформанси и побавно извршување на SQL барања.
За решавање на овој проблем користевме RANGE партиционирање базирано на временски атрибути, бидејќи податоците во системот се природно временски ориентирани, освен за билетите за нив користевме HASH партиционирање.
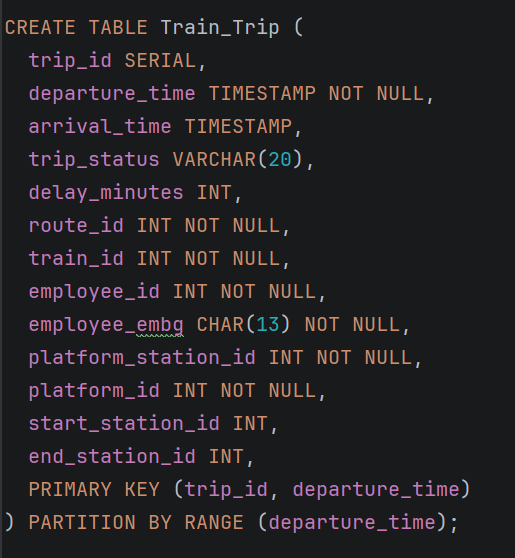
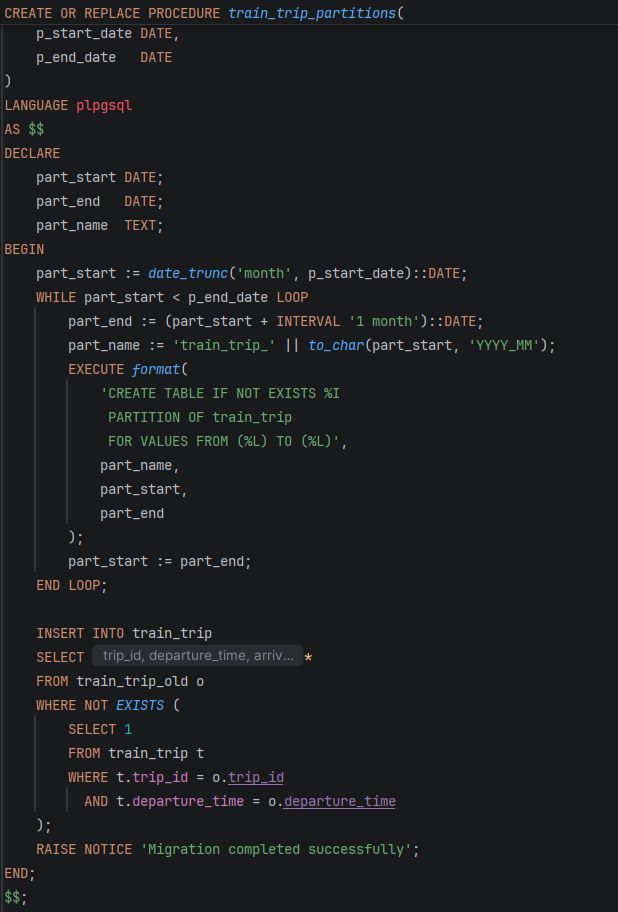
1. Train Trip табела – партиционирање по departure_time
Табелата Train_Trip претставува централна табела во системот, бидејќи ги содржи сите информации за железничките патувања, како што се времето на поаѓање и пристигнување, статусот на патувањето, поврзаниот воз, како и вработените кои учествуваат во неговото извршување.
Причини за партиционирање
- Висока фреквенција на податоци
Секојдневно се генерираат голем број нови патувања. Со тек на време, оваа табела станува една од најголемите во системот, што може значително да ги намали перформансите при пребарување и обработка на податоци.
- Природна временска структура
Секое патување има точно дефиниран атрибут departure_time. Овој атрибут е природно погоден за RANGE партиционирање, бидејќи податоците логички се групираат по временски интервали (месеци или години).
- Типични прашања во системот
Најчестите барања во системот се од типот:
- Сите патувања во одреден месец
- Патувања во одредена година
- Анализа на доцнења во одреден временски период
Овие операции бараат временско филтрирање, кое со партиционирање се извршува значително побрзо, бидејќи системот пристапува само до релевантната партиција.
- Како помага партиционирањето
Со примена на месечни партиции, PostgreSQL обработува само мал дел од податоците (околу 1/12 од годишните податоци), наместо целата табела. Ова значително ги подобрува перформансите на: SELECT операции, UPDATE операции и DELETE операции.
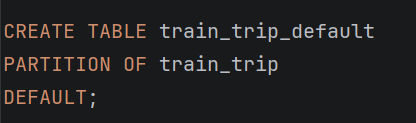
- DEFAULT партиција
Се користи и DEFAULT партиција која обезбедува стабилност на системот. Таа ги прима сите записи кои не спаѓаат во дефинираните временски опсези и спречува грешки при внесување на податоци.
Kод со објаснување
- STEP 1: Преименување на старата табела

-Се зачувуваат постоечките податоци во стара табела train_trip_old
-Ова овозможува безбедна миграција кон нова партиционирана структура
-Не се губат податоци
- STEP 2: Креирање на нова партиционирана табела

-Се креира нова главна табела train_trip
-Таа е parent (главна) партиционирана табела
-Податоците ќе се делат според departure_time
- STEP 3: Креирање DEFAULT партиција (сигурносна мрежа)

-Ги прима сите редови што не спаѓаат во дефинираните интервали
-Спречува грешки при INSERT
-Многу важно за стабилен систем
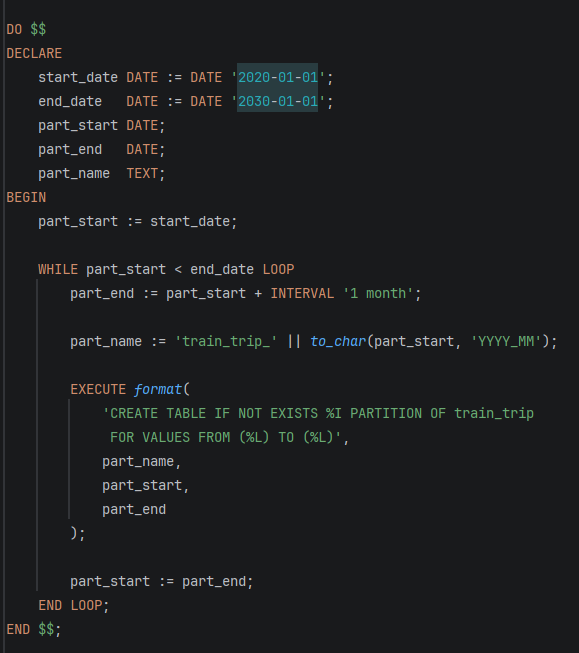
- STEP 4: Автоматско креирање партиции (динамички)

-Автоматски креира месечни партиции
-Почнува од 2020 до 2030
-Секоја партиција добива име: train_trip_2020_01, train_trip_2020_02 итн.
-Спречува рачно пишување на многу SQL команди
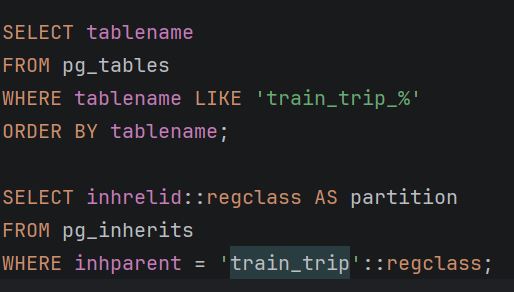
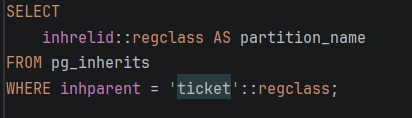
- STEP 5: Проверка на сите партиции

-Прикажува сите креирани партиции
-Проверка дали DO блокот работел
-Покажува кои табли се вистински партиции на train_trip
-Важно за проверка на правилна структура
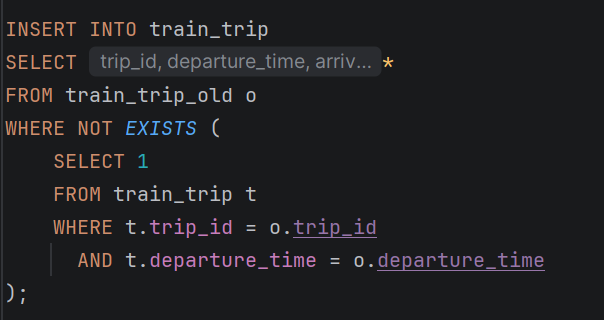
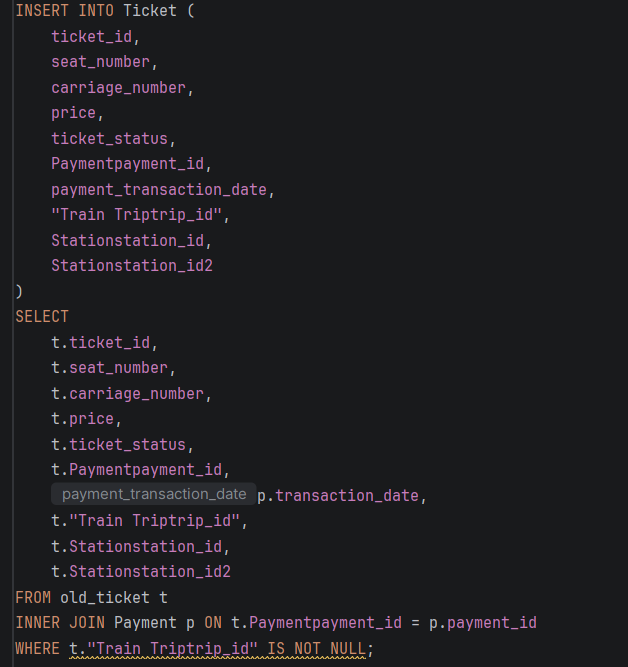
- STEP 6: Внесување податоци од стара табела

-Ги префрла старите податоци во новата структура
-Спречува дупликати
-Внесува само нови/недостасувачки редови
Заклучок
Со партиционирањето на табелата Train_Trip добиваме поделба на податоците во месечни табели (партиции) според departure_time. На тој начин пребарувањата се многу побрзи, бидејќи системот чита само податоци од конкретниот месец, наместо целата табела. Ова резултира со подобри перформанси, полесно одржување и поефикасна работа со големи количини на податоци.
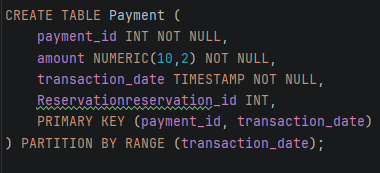
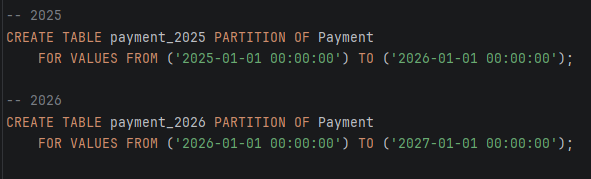
2. Payment табела – партиционирање по transaction_date
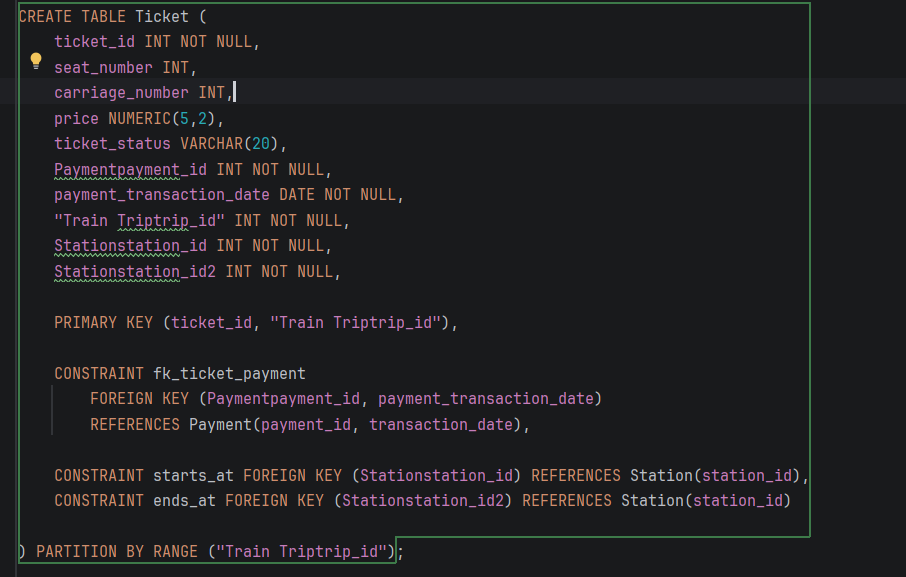
3. Ticket табела – партиционирање по ticket_id
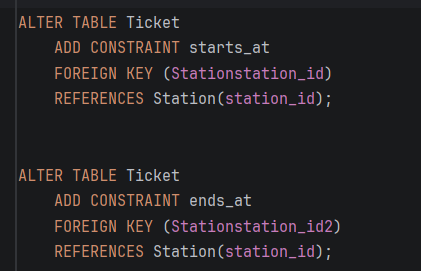
Табелата Ticket претставува една од трансакциски најоптоварените табели во системот, бидејќи во неа се зачувува секој купен билет за секое поединечно патување, вклучувајќи детали за седиштето, вагонот, цената и релевантните дестинации.
Причини за партиционирање
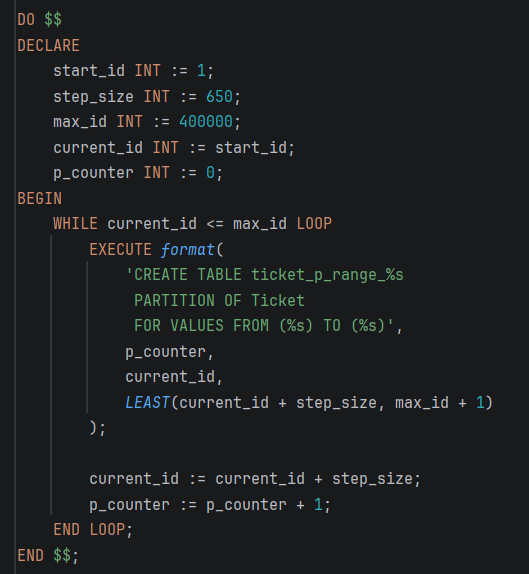
- Екстремно висок волумен на податоци Со симулација на над 12 милиони записи, оваа табела е критична за перформансите. Класично пребарување низ единечна табела од ваков размер предизвикува креирање на огромни индекси кои не можат да се соберат во RAM меморијата.
- Природа на пребарувањата (Клуч за партиционирање) За разлика од патувањата кои логички се пребаруваат по датум, билетите во реалниот систем најчесто се пребаруваат поединечно преку нивниот уникатен ID (
ticket_id) при валидација на станица или при проверка од кондуктер. Поради ова, HASH партиционирањето е најефикасниот избор.
- Паметна и рамномерна распределба Преку HASH партиционирање со користење на клучот
ticket_id, податоците математички се делат на еднакви делови. Наместо една масивна табела, системот користи 16 помали партиции каде што податоците се идеално распределени.
- Како помага партиционирањето Кога системот извршува прашање за конкретен
ticket_id, PostgreSQL врши брзо хаширање на бараниот ID и веднаш детерминира во која точно партиција се наоѓа билетот. Базата целосно ги игнорира останатите 15 партиции, со што драстично се крати времето на пребарување и се одржуваат мали и брзи индекси.
Kод со објаснување
Attachments (22)
- Screenshot 2026-05-21 185825.png (5.3 KB ) - added by 7 weeks ago.
- Screenshot 2026-05-21 190107.png (61.8 KB ) - added by 7 weeks ago.
- Screenshot 2026-05-21 190326.png (9.5 KB ) - added by 7 weeks ago.
- Screenshot 2026-05-21 190749.png (46.7 KB ) - added by 7 weeks ago.
- Screenshot 2026-05-21 190958.png (31.8 KB ) - added by 7 weeks ago.
- Screenshot 2026-05-21 191347.png (30.9 KB ) - added by 7 weeks ago.
- Old_ticket.png (4.1 KB ) - added by 7 weeks ago.
- Proverka dali site particii postojat.png (13.5 KB ) - added by 7 weeks ago.
- Screenshot 2026-05-22 015945.png (4.0 KB ) - added by 7 weeks ago.
- Screenshot 2026-05-22 015953.png (18.4 KB ) - added by 7 weeks ago.
- Screenshot 2026-05-22 020000.png (18.0 KB ) - added by 7 weeks ago.
- Screenshot 2026-05-22 020010.png (4.5 KB ) - added by 7 weeks ago.
- Screenshot 2026-05-22 020017.png (13.2 KB ) - added by 7 weeks ago.
- Screenshot 2026-05-22 122632.png (82.5 KB ) - added by 7 weeks ago.
- insert.png (62.0 KB ) - added by 7 weeks ago.
- new_table.png (77.8 KB ) - added by 7 weeks ago.
- particii.png (50.1 KB ) - added by 7 weeks ago.
- constraint.png (29.1 KB ) - added by 7 weeks ago.
- Bileti po particija.png (7.9 KB ) - added by 7 weeks ago.
- particii po mesec.png (18.0 KB ) - added by 7 weeks ago.
- vozovi po particija.png (16.3 KB ) - added by 7 weeks ago.
- finalna presmetka.png (11.3 KB ) - added by 7 weeks ago.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
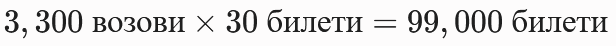{kind=link}
{kind=link}
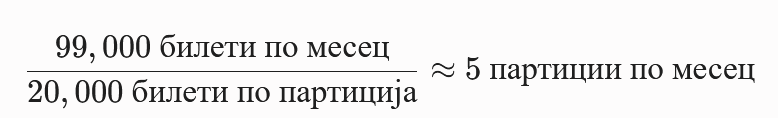{kind=link}
{kind=link}
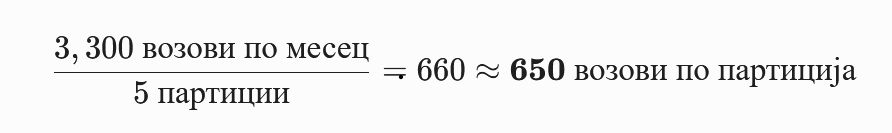{kind=link}
{kind=link}
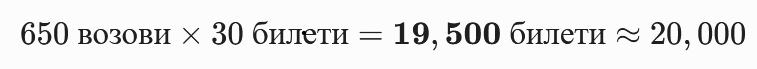{kind=link}
Download all attachments as: .zip