| Version 66 (modified by , 7 weeks ago) ( diff ) |
|---|
Напредна тема
Зошто се одлучивме за темата Партиционирање ?
Во овој проект се одлучивме да примениме партиционирање на табели (table partitioning) со цел да се подобрат перформансите, скалабилноста и одржливоста на базата на податоци. Системот претставува железничка платформа каде што се генерира голем обем на податоци, особено за патувања, билети и плаќања, кои со тек на време значително се зголемуваат. Поради тоа, класичен пристап со една голема табела би довел до намалени перформанси и побавно извршување на SQL барања.
За решавање на овој проблем користевме RANGE партиционирање базирано на временски атрибути, бидејќи податоците во системот се природно временски ориентирани, освен за билетите за нив користевме HASH партиционирање.
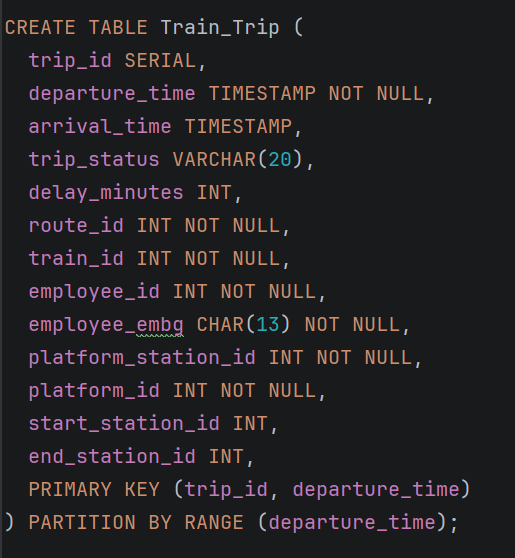
1. Train Trip табела – партиционирање по departure_time
Табелата Train_Trip претставува централна табела во системот, бидејќи ги содржи сите информации за железничките патувања, како што се времето на поаѓање и пристигнување, статусот на патувањето, поврзаниот воз, како и вработените кои учествуваат во неговото извршување.
Причини за партиционирање
- Висока фреквенција на податоци
Секојдневно се генерираат голем број нови патувања. Со тек на време, оваа табела станува една од најголемите во системот, што може значително да ги намали перформансите при пребарување и обработка на податоци.
- Природна временска структура
Секое патување има точно дефиниран атрибут departure_time. Овој атрибут е природно погоден за RANGE партиционирање, бидејќи податоците логички се групираат по временски интервали (месеци или години).
- Типични прашања во системот
Најчестите барања во системот се од типот:
- Сите патувања во одреден месец
- Патувања во одредена година
- Анализа на доцнења во одреден временски период
Овие операции бараат временско филтрирање, кое со партиционирање се извршува значително побрзо, бидејќи системот пристапува само до релевантната партиција.
- Како помага партиционирањето
Со примена на месечни партиции, PostgreSQL обработува само мал дел од податоците (околу 1/12 од годишните податоци), наместо целата табела. Ова значително ги подобрува перформансите на: SELECT операции, UPDATE операции и DELETE операции.
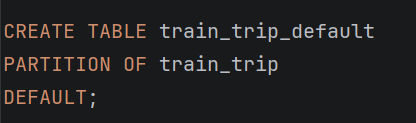
- DEFAULT партиција
Се користи и DEFAULT партиција која обезбедува стабилност на системот. Таа ги прима сите записи кои не спаѓаат во дефинираните временски опсези и спречува грешки при внесување на податоци.
Kод со објаснување
- STEP 1: Преименување на старата табела

-Се зачувуваат постоечките податоци во стара табела train_trip_old
-Ова овозможува безбедна миграција кон нова партиционирана структура
-Не се губат податоци
- STEP 2: Креирање на нова партиционирана табела

-Се креира нова главна табела train_trip
-Таа е parent (главна) партиционирана табела
-Податоците ќе се делат според departure_time
- STEP 3: Креирање DEFAULT партиција (сигурносна мрежа)

-Ги прима сите редови што не спаѓаат во дефинираните интервали
-Спречува грешки при INSERT
-Многу важно за стабилен систем
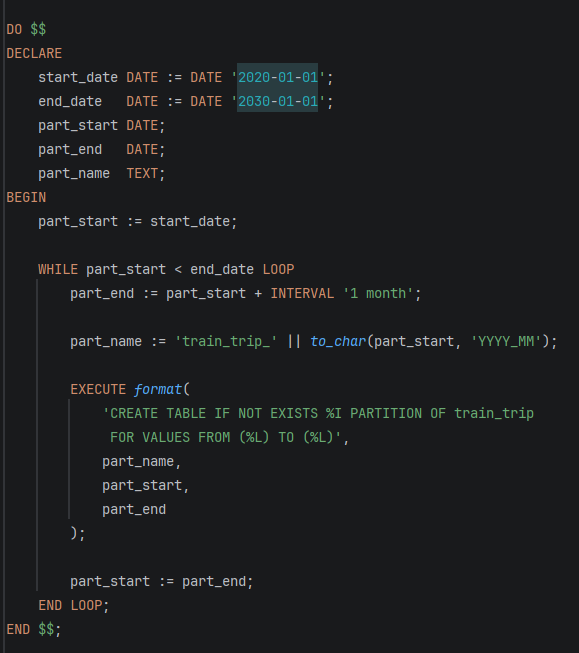
- STEP 4: Автоматско креирање партиции (динамички)

-Автоматски креира месечни партиции
-Почнува од 2020 до 2030
-Секоја партиција добива име: train_trip_2020_01, train_trip_2020_02 итн.
-Спречува рачно пишување на многу SQL команди
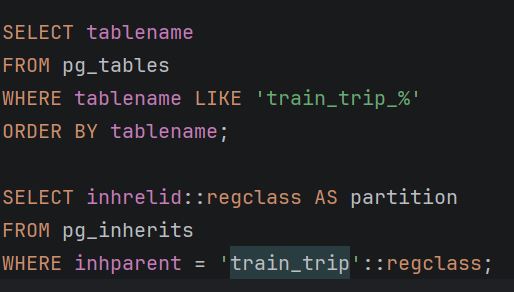
- STEP 5: Проверка на сите партиции

-Прикажува сите креирани партиции
-Проверка дали DO блокот работел
-Покажува кои табли се вистински партиции на train_trip
-Важно за проверка на правилна структура
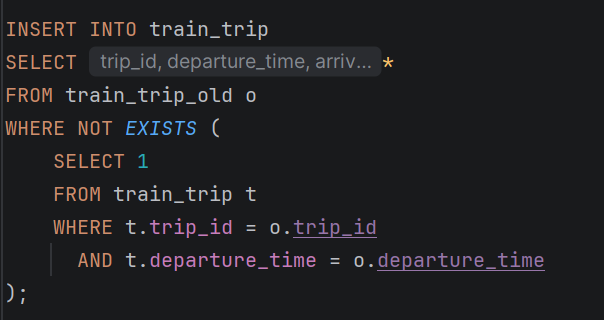
- STEP 6: Внесување податоци од стара табела

-Ги префрла старите податоци во новата структура
-Спречува дупликати
-Внесува само нови/недостасувачки редови
Оптимизација
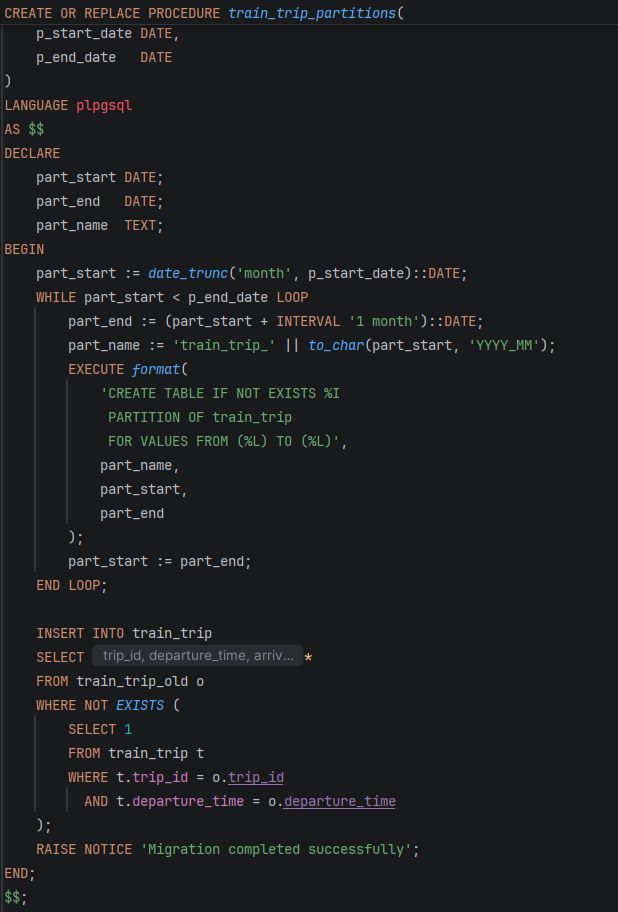
Со цел да се автоматизира процесот на креирање на партиции, беше имплементирана процедурата train_trip_partitions. Оваа процедура овозможува динамичко креирање на месечни партиции за табелата Train_Trip врз основа на временски интервал внесен од корисникот.
Процедурата прима два параметри: p_start_date – почетен датум и p_end_date – краен датум. Врз основа на овие вредности, автоматски се генерираат партиции за секој месец во зададениот период. Секоја партиција добива име во формат train_trip_YYYY_MM, што овозможува подобра организација и полесно управување со податоците.

Дополнително, процедурата автоматски ги мигрира податоците од старата табела train_trip_old во новата партиционирана структура. При тоа се користи NOT EXISTS проверка за да се спречи внесување на дупликати записи.
Со оваа функционалност се автоматизира целиот процес на партиционирање, се намалува потребата од рачно креирање на партиции, се подобрува одржувањето на системот и се обезбедува подобра скалабилност и перформанса при работа со големи количини на податоци.
Заклучок
Со партиционирањето на табелата Train_Trip добиваме поделба на податоците во месечни табели (партиции) според departure_time. На тој начин пребарувањата се многу побрзи, бидејќи системот чита само податоци од конкретниот месец, наместо целата табела. Ова резултира со подобри перформанси, полесно одржување и поефикасна работа со големи количини на податоци.
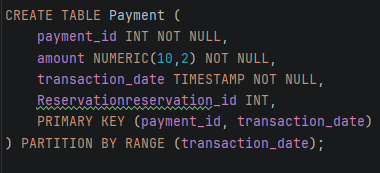
2. Payment табела – партиционирање по transaction_date
Табелата Payment претставува централна финансиска табела во системот, бидејќи ги содржи сите информации за извршените плаќања, како што се износот на трансакцијата, датумот и времето на плаќањето, како и поврзаната резервација.
Причини за партиционирање
- Константен и брз раст на податоци
Секојдневно се генерираат голем број нови трансакции. Со тек на време, оваа табела станува една од најголемите во системот, што може значително да ги намали перформансите при пребарување и обработка на финансиски податоци.
- Природна временска структура
Секое плаќање има точно дефиниран атрибут transaction_date. Овој атрибут е природно погоден за RANGE партиционирање, бидејќи финансиските записи логички се групираат по временски интервали, а исто така одговара на потребите за финансиско известување и ревизија.
Овие операции бараат временско филтрирање, кое со партиционирање се извршува значително побрзо, бидејќи системот пристапува само до релевантната партиција.
- Како помага партиционирањето
Со примена на годишни партиции, PostgreSQL ги изолира податоците по години. Кога сметководството бара извештај за 2026 година, базата целосно ги игнорира (не ги ни чита на хард дискот) податоците за другите години. Ова обезбедува инстантни резултати на SELECT аналитичките операции и овозможува побрзо архивирање на старите податоци.
- Default партиција
Се користи и DEFAULT партиција која служи како сигурносен механизам за стабилноста на апликацијата. Таа ги прифаќа сите плаќања чии датуми поради системска грешка или неусогласено време паѓаат надвор од предвидениот опсег, со што се спречува паѓање на трансакцијата при купување билет.
Kод со објаснување
- STEP 1: Преименување на старата табела

-Пред да се направи каква било промена, старата табела се преименува во payment_original. На овој начин сите постоечки финансиски записи остануваат недопрени и може да се користат при миграцијата.
- STEP 2: Креирање на нова партиционирана табела

-Се креира новата главна табела Payment со PARTITION BY RANGE (transaction_date). Важно е transaction_date да биде вклучен во PRIMARY KEY – тоа е барање на PostgreSQL кога табелата е партиционирана. Оваа табела сама по себе не чува податоци, туку служи само како логичка обвивка над партициите.
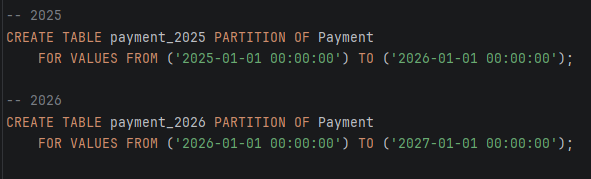
- STEP 3: Партиција по години

-Податоците се партиционираат по години, при што секоја партиција го покрива целосниот период од почетокот до крајот на соодветната година. Горната граница на секој опсег е ексклузивна, со што се осигурува дека записите прецизно и без преклопување се распоредуваат во точната партиција.
- STEP 4: Креирање DEFAULT партиција

-Секој запис чиј transaction_date не спаѓа во опсегот, автоматски завршува во оваа партиција. Ова е важен механизам – без него, INSERT со датум надвор од опсегот би предизвикал грешка и би го нарушил работењето на системот
- STEP 5: Миграција на постоечките податоци

-Сите записи од payment_original се пренесуваат во новата партиционирана табела. PostgreSQL автоматски одлучува во која партиција оди секој запис врз основа на неговиот transaction_date.
Заклучок
Со партиционирањето на табелата Payment добиваме поделба на финансиските трансакции во годишни табели (партиции) според transaction_date. На тој начин пребарувањата се многу побрзи, бидејќи системот чита само податоци од конкретната година, наместо целата табела. Ова резултира со подобри перформанси, полесно одржување и поефикасна работа со големи количини на трансакциски податоци.
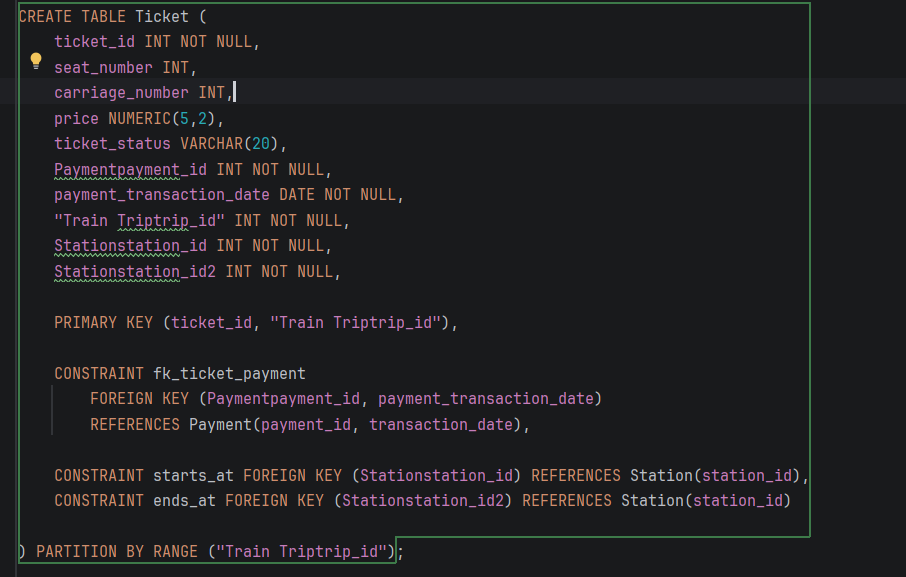
3. Ticket табела – партиционирање по Train Trip_id
Табелата Ticket претставува една од трансакциски најоптоварените табели во системот, бидејќи во неа се зачувува секој купен билет за секое поединечно патување, вклучувајќи детали за седиштето, вагонот, цената и релевантните дестинации.
Причини за партиционирање
- Природата на табелата како релациски јазол Табелата Ticket функционира како централна агрегациска табела која ги поврзува Train_Trip (патувањата) и Payment (плаќањата) – двата ентитети со најголем секојдневен прилив на податоци во целиот систем. Бидејќи секое патување продуцира стотици продадени билети, а секое плаќање резултира со фискален запис за билет, волуменот во оваа табела се мултиплицира експоненцијално во споредба со останатите табели.
- Екстремно висок волумен на податоци Бидејќи табелата моментално содржи 12 милиони записи, и при секое ново плаќање се прави нов тикет, оваа табела станува критична за перформансите. Без партиционирање, секое пребарување би морало да скенира милиони редови истовремено.
- Природа на пребарувањата (Клуч за партиционирање)Билетите во реалниот систем најчесто се пребаруваат во контекст на одредено патување – при валидација на станица, при проверка од кондуктер или при преглед на резервации за конкретен воз. Поради ова, RANGE партиционирањето по Train Triptrip_id е најлогичен избор, бидејќи сите билети кои припаѓаат на исто патување физички се наоѓаат во иста партиција.
- Еден тикет – една партицијаКлучна забелешка во дизајнот е дека еден тикет не смее да се појавува во две различни партиции (ниту во Payment ниту во Train Trip). Со партиционирање по Train Triptrip_id, ова е гарантирано – секој тикет логички и физички припаѓа на точно едно патување и со тоа на точно една партиција.
- Рамномерна распределба Преку RANGE партиционирање со чекор од 650 trip_id вредности по партиција, системот создава партиции со предвидлива и контролирана големина. Со вкупно ~400,000 Train Trip записи и ~30 тикети по патување, секоја партиција содржи приближно ~19,500 записи, со што се задоволува барањето за партиции од ~20,000 редови.
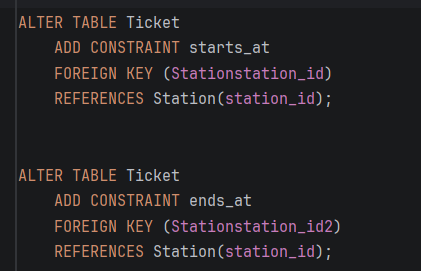
- Усогласеност со Payment преку transaction_date За да се спречи појавување на еден тикет во две партиции на Payment, во Ticket табелата е додадена колоната payment_transaction_date. На овој начин, Foreign Key кон Payment е составен (composite) клуч (payment_id, transaction_date), кој директно одговара на партицискиот клуч на Payment табелата.
- Математичко објаснување на партиционирањето ПресметкаБидејќи партициите на Train Trip се поделени по месеци и содржат по ~3,300 возови за една месечна партиција.
Пресметка на билети по месечна партиција:

Тоа значи дека една месечна партиција на Train Trip е преголема за директно пресликување во една партиција на Ticket. За да се добијат партиции од препорачаните ~20,000 редови, секој месец мора логаритамски да се „исече“ на помали парчиња:

Со тоа, опсегот на train_trip_id во една партиција на Ticket треба да биде:
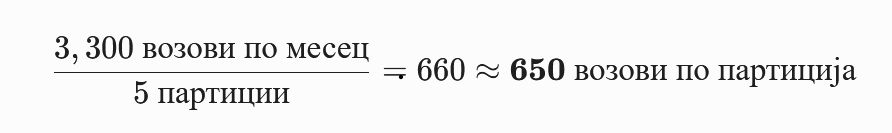

Зошто по точно 650?
Бидејќи train_trip_id се доделуваат последователно (1, 2, 3...), во еден месец ID-ата се движат во строго дефиниран континуиран опсег. Ова овозможува директно следење на партициите на Train Trip, но со прецизно сечење на 5 помали пакувања по месец.
Со овој пристап секоја партиција на Ticket директно кореспондира со точно дефиниран подопсег од месечна партиција на Train Trip, со што се гарантира:
- Еден тикет се наоѓа во точно една партиција.
- Секоја партиција содржи стабилни ~19,500 записи.
- PostgreSQL може максимално да примени Partition Pruning при JOIN операции меѓу билетите и возовите.
- Партициите на Ticket и Train Trip се логички и структурно усогласени.
Финална проверка на капацитетот:
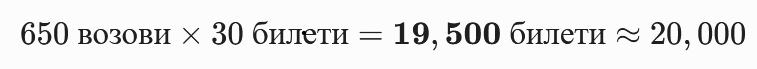

Kод со објаснување
- STEP 1: Преименување на старата табела

-Се зачувуваат постоечките податоци во стара табела old_ticket
-Ова овозможува безбедна миграција кон нова партиционирана структура
-Не се губат претходно генерираните податоци
- STEP 2: Креирање на нова партиционирана табела

-Се креира нова главна табела Ticket која служи како parent табела
-Податоците се дефинирани да се делат со PARTITION BY RANGE ("Train Triptrip_id").
-Примарниот клуч е составен (composite): (ticket_id, "Train Triptrip_id") – задолжително бидејќи партицискиот клуч мора да биде дел од PRIMARY KEY во PostgreSQL.
-Додадена е колоната payment_transaction_date за да се овозможи composite Foreign Key кон Payment, со цел усогласување на партициите.
 -Дополнителни constraints кои треба да се запазат при внес на податоците во новата табела.
-Дополнителни constraints кои треба да се запазат при внес на податоците во новата табела.
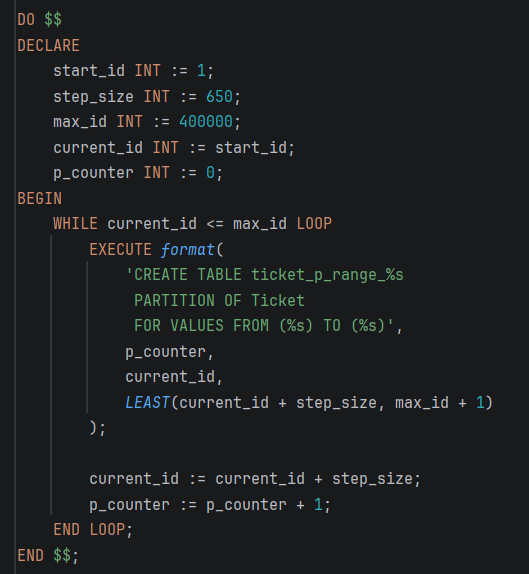
- STEP 3: Автоматско креирање партиции (динамички преку DO блок)

-Се користи динамички DO блок со WHILE јамка за автоматизација.Автоматски се креираат ~616 партиции (400,000 / 650 ~ 616) именувани ticket_p_range_0 до ticket_p_range_615.
-Секоја партиција покрива опсег од 650 trip_id вредности, односно приближно ~19,500 тикети по партиција.
-LEAST(current_id + step_size, max_id + 1) спречува излегување надвор од дефинираниот опсег при последната партиција.
-Спречува мануелно пишување на стотици посебни SQL команди за креирање табели.
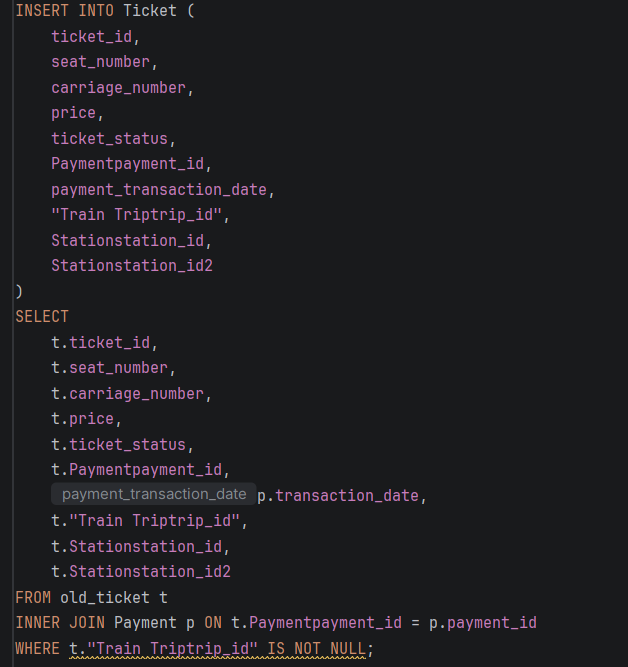
- STEP 4: Внесување податоци од стара табела (Миграција)

-Ги префрла сите зачувани записи од old_ticket во новата партиционирана структура.
-INNER JOIN Payment е неопходен за да се добие transaction_date, бидејќи таа колона не постоела во старата табела.
-WHERE "Train Triptrip_id" IS NOT NULL ги исклучува некомплетните записи кои не можат да се распределат во партиција.
-PostgreSQL автоматски во позадина ги распределува редовите низ партициите врз основа на вредноста на Train Triptrip_id.
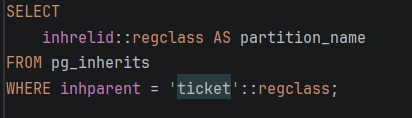
- STEP 5: Проверка на сите партиции

-Врши селекција од системската табела pg_inherits
-Ги прикажува сите реално креирани партиции под главната табела ticket
-Служи како потврда за успешна структура на базата
Заклучок
Со имплементација на RANGE партиционирање на табелата Ticket по Train Triptrip_id, успеавме масовниот волумен од 12 милиони записи да го поделиме на ~616 рамномерни физички табели од приближно ~19,500 записи секоја. Пребарувањето на билетите сега се извршува моментално бидејќи PostgreSQL точно знае во која под-табела се наоѓа бараниот тикет врз основа на патувањето.
Дополнително, усогласувањето со партициите на Payment преку composite Foreign Key гарантира дека еден тикет никогаш не се појавува во две различни партиции. Ова резултира со драстично намалување на оптоварувањето, побрз одзив на системот и долгорочна скалабилност на железничката платформа.
Attachments (22)
- Screenshot 2026-05-21 185825.png (5.3 KB ) - added by 7 weeks ago.
- Screenshot 2026-05-21 190107.png (61.8 KB ) - added by 7 weeks ago.
- Screenshot 2026-05-21 190326.png (9.5 KB ) - added by 7 weeks ago.
- Screenshot 2026-05-21 190749.png (46.7 KB ) - added by 7 weeks ago.
- Screenshot 2026-05-21 190958.png (31.8 KB ) - added by 7 weeks ago.
- Screenshot 2026-05-21 191347.png (30.9 KB ) - added by 7 weeks ago.
- Old_ticket.png (4.1 KB ) - added by 7 weeks ago.
- Proverka dali site particii postojat.png (13.5 KB ) - added by 7 weeks ago.
- Screenshot 2026-05-22 015945.png (4.0 KB ) - added by 7 weeks ago.
- Screenshot 2026-05-22 015953.png (18.4 KB ) - added by 7 weeks ago.
- Screenshot 2026-05-22 020000.png (18.0 KB ) - added by 7 weeks ago.
- Screenshot 2026-05-22 020010.png (4.5 KB ) - added by 7 weeks ago.
- Screenshot 2026-05-22 020017.png (13.2 KB ) - added by 7 weeks ago.
- Screenshot 2026-05-22 122632.png (82.5 KB ) - added by 7 weeks ago.
- insert.png (62.0 KB ) - added by 7 weeks ago.
- new_table.png (77.8 KB ) - added by 7 weeks ago.
- particii.png (50.1 KB ) - added by 7 weeks ago.
- constraint.png (29.1 KB ) - added by 7 weeks ago.
- Bileti po particija.png (7.9 KB ) - added by 7 weeks ago.
- particii po mesec.png (18.0 KB ) - added by 7 weeks ago.
- vozovi po particija.png (16.3 KB ) - added by 7 weeks ago.
- finalna presmetka.png (11.3 KB ) - added by 7 weeks ago.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
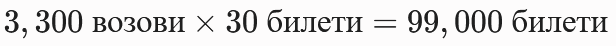{kind=link}
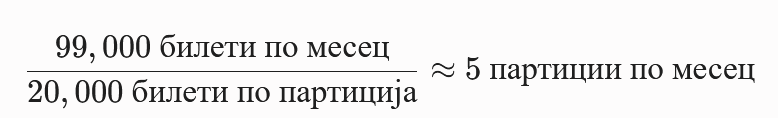{kind=link}
Download all attachments as: .zip