| Version 5 (modified by , 7 weeks ago) ( diff ) |
|---|
Advanced Phase
Опис
Имплементација на систем за препораки базиран на AI embeddings користејќи pgvector екстензија за PostgreSQL. Секоја активност, услуга и опрема добива своја векторска репрезентација (embedding) на нејзиниот опис, а системот наоѓа математички слични записи преку cosine similarity.
Како функционира?
Основната идеја е дека текстот (опис на активност, услуга или опрема) се претвора во вектор — листа од броеви каде секој број го претставува значењето на зборот во тој текст. Колку се векторите поблиску математички, толку се посличните записи.
Опис на запис → AI модел → Vector [0.23, 0.89, ...] → Слични записи
Чекори
- Чекор 1
Инсталација на pgvector во Docker контејнерот и активирање на екстензијата во PostgreSQL
docker exec -it camping-postgres bash -c \ "apt-get update && apt-get install -y postgresql-16-pgvector"
CREATE EXTENSION IF NOT EXISTS vector;
- Чекор 2
На табелите Activity, Service и Equipment се додава нова колона од тип vector(384). Димензијата 384 одговара на моделот all-MiniLM-L6-v2 кој се користи за генерирање на embeddings.
ALTER TABLE Activity ADD COLUMN embedding vector(384); ALTER TABLE Service ADD COLUMN embedding vector(384); ALTER TABLE Equipment ADD COLUMN embedding vector(384)
- Чекор 3
Embeddings се генерираат преку Python скрипта која користи sentence-transformers библиотека.
Инсталација на потребните библиотеки
pip install sentence-transformers psycopg2-binary python-dotenv
Во .env фајлот ги пополнуваме HOST, PORT, NAME, USER, PASSWORD.
Креираме python скрипта generate_embeddings.py
import psycopg2
from sentence_transformers import SentenceTransformer
from dotenv import load_dotenv
import os
load_dotenv()
conn = psycopg2.connect(
host=os.getenv("DB_HOST"),
port=os.getenv("DB_PORT"),
database=os.getenv("DB_NAME"),
user=os.getenv("DB_USER"),
password=os.getenv("DB_PASSWORD")
)
cursor = conn.cursor()
model = SentenceTransformer('all-MiniLM-L6-v2')
# Embeddings za Activity
print("Generating embeddings for activities...")
cursor.execute("SELECT activity_id, description FROM Activity WHERE description IS NOT NULL")
activities = cursor.fetchall()
for activity_id, description in activities:
embedding = model.encode(description).tolist()
cursor.execute(
"UPDATE Activity SET embedding = %s WHERE activity_id = %s",
(embedding, activity_id)
)
conn.commit()
print(f"Done! {len(activities)} activities executed.")
# Embeddings za Service
print("Generating embeddings for services...")
cursor.execute("SELECT serviceId, description FROM Service WHERE description IS NOT NULL")
services = cursor.fetchall()
for service_id, description in services:
embedding = model.encode(description).tolist()
cursor.execute(
"UPDATE Service SET embedding = %s WHERE serviceId = %s",
(embedding, service_id)
)
conn.commit()
print(f"Done! {len(services)} services executed.")
# Embeddings za Equipment
print("Generating embeddings for Equipment...")
cursor.execute("SELECT equipmentId, description FROM Equipment WHERE description IS NOT NULL")
equipments = cursor.fetchall()
for equipment_id, description in equipments:
embedding = model.encode(description).tolist()
cursor.execute(
"UPDATE Equipment SET embedding = %s WHERE equipmentId = %s",
(embedding, equipment_id)
)
conn.commit()
print(f"Done! {len(equipments)} equipments executed.")
cursor.close()
conn.close()
- Чекор 4
За брзо пребарување по сличност се креираат ivfflat индекси. Со ivfflat индекс векторите се групираат во кластери и се пребарува само во најблиските — многу побрзо.
- Чекор 5
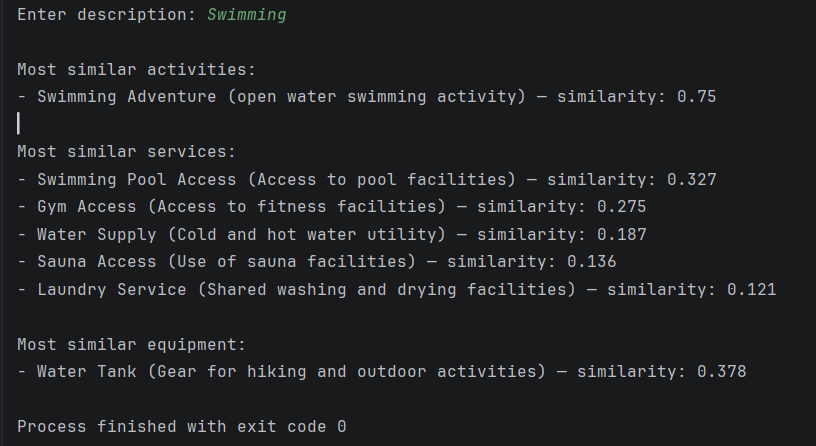
Се креираат PostgreSQL функции кои примаат вектор и враќаат N најслични записи сортирани по cosine similarity.
Attachments (1)
- search_recommendations_swimming.png (63.7 KB ) - added by 7 weeks ago.
{kind=link}
{kind=link}
Download all attachments as: .zip