| Version 8 (modified by , 2 months ago) ( diff ) |
|---|
Профилирање и оптимизација на прашалници
Во базите на податоци претставуваат критична компонента за успешното функционирање на апликациите. Како што расте волуменот на податоците и комплексноста на прашалницте, перформансите на базата стануваат тесно грло кое има влијание врз генералните перформанси на апликацијата, оперативната ефикасност и најважно, врз кориснчкото искуство. Еден од најчестите проблеми во администрацијата на базите се неефикасните SQL прашалници, особено кога се работи за комплексни аналитички прашалници што обработуваат големи количини на податоци и притоа прават комплексни пресметки и агрегации, и ова дополнително ги комплицира работите доколку ваквите аналитички прашалници се извршуваат врз оперативната база на податоци. Во продолжение е прикажан пример, како едноствна промена во начинот на калкулирање на еден сегмент од овој прашлник, доведе до драстично подобрување на времето на извршување.
Преглед на првичниот проблем
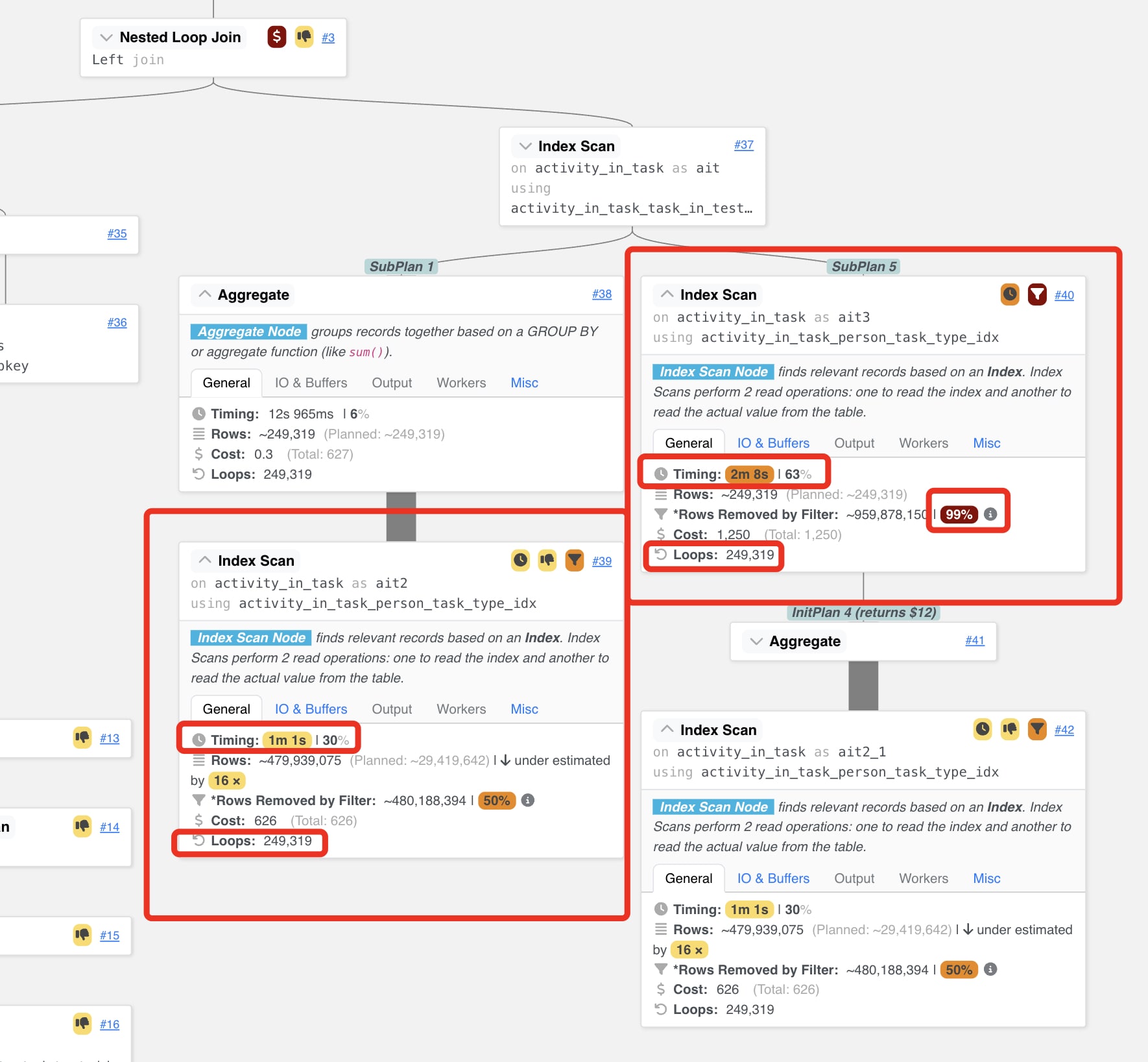
Како пример за овој дел од проектот го земавме погледот за извесна статистичка анализа на резултатите на студентите по задача, v_statistiki_vremenski_po_student_i_zadacha. Иако навидум овој поглед сам по себе изгледа доста комплексен, проблем всушност прозилезе дека е во v_activity_with_interval_and_payload_next, каде што во потпрашалници се прави пресметка за времето на првата активност пред моментално разгледуваната и првата активност по моментално разгледуваната. Времето на извршување на прашалникот вклучувајќи ги вакви операции во просек надминуваше 3 минути врз табела со околу 500.000 записи.
(SELECT ait3.payload AS payload_next
FROM activity_in_task ait3
WHERE ait3.person_id = pppppp.person_id AND ait3.task_in_test_instance_id = pppppp.task_in_test_instance_id AND
ait3.when_occured = pppppp.when_occured_next) AS payload_next
(SELECT min(ait2.when_occured) AS min
FROM activity_in_task ait2
WHERE ait2.person_id = ait.person_id AND ait2.task_in_test_instance_id = ait.task_in_test_instance_id AND
ait2.when_occured > ait.when_occured) AS when_occured_next
Како дојдовме до ваков заклучок?
Детална анализа на Execution Plan
Execution планот (план на извршување) е најмоќната алатка за да го разбереме "начинот на размислување" на оптимизаторот, и да најдеме потенцијални точки за подобрување. Со негова анализа може да се утврди:
- кои индекси (не) се користат,
- дали се прават целосни скенирања на табела (table scans),
- дали се прават непотребни сортирања или спојувања,
- колкави се проценетите и реалните броеви на редови што се процесираат.
Основни концепти за читање и разбирање на Execution Plans
1. Структура на планот
Execution планот е во форма на хиерархиска структура (дрво) каде што:
Корен е конечниот резултат на прашачникот
Листови се основните табели или индекси
Внатрешни јазли се операциите (JOIN, WHERE, GROUP BY, итн.)
Текот на податоците е оздола нагоре
2. Клучни метрики во планот
Cost (Цена на извршување): cost=0.43..156789.45
Првиот број (0.43) е startup cost - цена до враќање на првиот ред Вториот број (156789.45) е total cost - цена по враќање на сите редови Цената е релативна единица, не се мери во време
Rows (Редови): rows=1000
Проценет број на редови што ќе се вратат од оваа операција Базиран на статистики на планерот
Width (Ширина): width=64
Просечна големина на редот во бајти
Actual Time (Реално време): actual time=180000.123..180456.789
Реалното време во милисекунди Првиот број е време до првиот ред Вториот број е вкупно време
Loops (Циклуси): loops=1000
Колку пати се извршила операцијата Вкупното време = actual time × loops
3. Типови операции во планот
Scan операции:
Seq Scan - Секвенцијално скенирање (ја чита цела табела)
Index Scan - Користи индекс за пронаоѓање на потребните редици
Index Only Scan - Сите потребни податоци се во индексот
Bitmap Heap Scan - Комбинира повеќе индекси
Join операции:
Nested Loop - За секој ред од левата табела, пребарува во десната (многу спора операција)
Hash Join - Создава hash табела и спојува по клучот
Merge Join - Спојува два сортирани сетови
Aggregate операции:
Aggregate - GROUP BY, COUNT, SUM, итн.
WindowAgg - Window функции (LEAD, LAG, ROW_NUMBER, итн.)
HashAggregate - GROUP BY со hash табела
Анализа на нашиот конкретен случај
За визуелизација на execution plan-от ја користевме следната алатка https://explain.dalibo.com/
За да имаме преглед и врз меморијата што се користи, ја извршивме следната команда за да генерираме execution plan
explain (analyze, buffers) select * from v_statistiki_vremenski_po_student_i_zadacha;
Очигледно беше дека операцијата NestedLoopJoin во рамки на која понатаму се прави IndexScan е онаа операција која е причина за лошите перформанси на прашалникот. На сликата подолу е видливо дека на овие операции практично отпаѓа целото време на извршување. Дополнително, можеме да воочиме дека естимацијата направена во однос на редови кои треба да се вратат е непрезицна и дека за секој ред од табелата ова скенирање се повторува.

Аплицирање на промената во прашалникот
lead(ait.when_occured) over (
partition by ait.person_id, ait.task_in_test_instance_id
order by ait.when_occured
) AS when_occured_next,
lead(ait.payload) over (
partition by ait.person_id, ait.task_in_test_instance_id
order by ait.when_occured
) as payload_next
Главната оптимизација се состоеше во замена на корелираните потпрашалници со window функции во погледот v_activity_with_interval_and_payload_next.

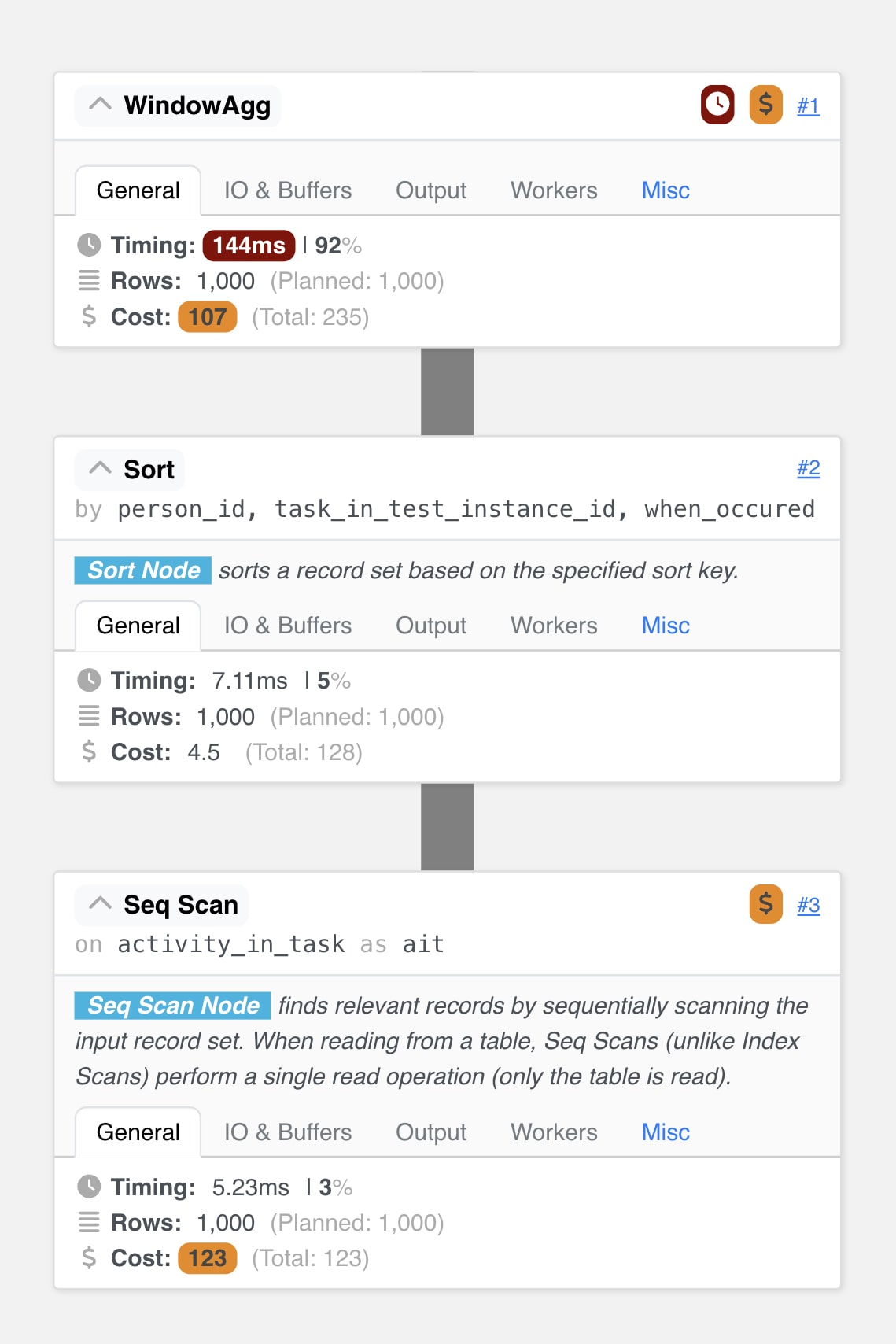
По аплицирање на оптимизацијата промената беше веднаш видлива и во планот на извршување. Претходно скапата операција на NestedLoop која траеше околу 3 минути, сега е заменета со WindowAgg која трае вкупно 144 ms. По ова веднаш беше видливо и подобрување во вкупното време на извршување на прашалникот кое драстично се намали на ~200ms.
Зошто Window функциите се толку поефикасни?
- Еднократно скенирање на табелата: Window функциите поминуваат само еднаш низ податоците, додека корелираните потпрашалници го скенираат истиот сет на податоци повторно за секој ред
- Нема повторливи пребарувања: Корелираните потпрашалници се извршуваат N пати (каде што N е бројот на редови), што резултира со O(N²) сложеност
- Подобра оптимизација: Современите планери (PostgreSQL, SQL Server, Oracle) користат специјализирани алгоритми за оптимизација на window функции
- Намален број на I/O операции: Наместо повеќе извршувања на потпрашалници со потенцијални пристапи до диск, сè се процесира во РАМ во една ефикасна операција
- Подобро искористување на индексите: Планерот може лесно да ги оптимизира window функциите, особено кога има индекси на колоните во
PARTITION BYиORDER BY, што најчесто ќе биде случај бидејќи тоа се колони на надворешни клучеви и посекако се користат за спојувања во обични прашалници.
Attachments (2)
- ex_before-min.jpg (244.6 KB ) - added by 2 months ago.
- ex_plan_windows-min.jpg (136.9 KB ) - added by 2 months ago.
{kind=link}
{kind=link}
Download all attachments as: .zip