| Version 5 (modified by , 7 months ago) ( diff ) |
|---|
Датотечни системи и организација на податоци
Во PostgreSQL, сите конфигурациски фајлови и фајлови со податоци кои ѝ припаѓаат на една база на податоци се сместени во посебен директориум наречен PGDATA. Овој директориум претставува физичката локација на целата инстанца на PostgreSQL, односно целиот „кластер“ со бази што ги управува таа инстанца.
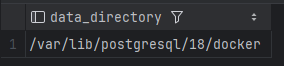
Типична локација за PGDATA е, на пример: /var/lib/postgresql/data или /var/lib/pgsql/data. Со извршување на прашалникот:
SHOW data_directory;
може да видиме каде PostgreSQL ги складира податоците за базата.

Во мојот конкретен пример имам наместено PostgreSQL да ги скалдира на локација /var/lib/postgresql/18/docker како што е наведено во официјалната документација на docker image-от за PostgreSQL. Исто така една важна карактеристика е тоа што на една иста машина можат да постојат повеќе независни PostgreSQL кластери, при што секој кластер се стартува од посебна серверска инстанца и има свој посебен PGDATA директориум.
Во рамките на PGDATA се наоѓаат повеќе поддиректориуми и контролни фајлови кои го дефинираат начинот на складирање и структурата на системот. Некој од овие поддиректориуми се:
- base - Поддиректориум што ги содржи сите кориснички бази на податоци, организирани по нивниот OID.
- global - Поддиректориум што содржи кластер-широки системски табели и глобални каталози.
- pg_wal - Поддиректориум што ги содржи Write-Ahead Log (WAL) фајловите за durability и recovery.
- pg_toast - Поддиректориум што ги содржи TOAST табелите за складирање на големи вредности (TEXT/BYTEA).
- pg_tblspc - Поддиректориум што содржи симболички линкови до tablespaces сместени надвор од PGDATA.
Вообичаено, во овој директориум се наоѓаат и конфигурациските фајлови:
- postgresql.conf - главна конфигурација на серверот
- pg_hba.conf - правила за автентикација
- pg_ident.conf - мапирање на кориснички имиња
Иако традиционално се чуваат во PGDATA, PostgreSQL дозволува и нивно сместување на друга локација, што овозможува поголема флексибилност при администрирање на системот.
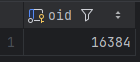
За секоја база на податоци во кластерот има посебен поддиректориум во PGDATA/base именуван според OID-то(Object identifier) на базата кој што може да се најде во pg_database.
Тоа може да го видиме со следниот прашалник:
SELECT oid FROM pg_database WHERE datname = 'film_rental';

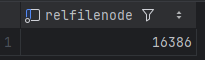
Во овој поддиректориум се чуваат сите датотеки што припаѓаат на таа база, вклучувајќи ги и системските каталози (системски табели што содржат метаподатоци за базата). PostgreSQL секоја табела и индекс ги чува во посебна датотека. За обични табели и индекси, името на датотеката е всушност filenode бројот (физички идентификатор на датотеката) кој може да се провери во pg_class.relfilenode колоната
Пример прашалник за табелата actor
SELECT relfilenode FROM pg_class WHERE relname = 'actor';

За привремени табели, PostgreSQL користи поразличен формат на име tBBB_FFF, каде BBB е ID на процесот што ја креирал табелата, а FFF е filenode бројот. Покрај главната датотека, PostgreSQL создава и дополнителни датотеки за секоја табела и индекс:
- Free Space Map (FSM) - датотека со суфикс _fsm која евидентира колку слободен простор има на располагање во табелата за новите податоци. На пример ако filenode на релација е 12345 FSM е складиран во file наречен 12345_fsm во истиот директориум како фајлот со главната релација.
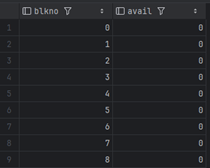
Пример прашалник за проверка на слободниот простор на сите страници за табелата actor:
SELECT *
FROM pg_freespace('actor');

Резултатот ги прикажува бројот на страницата (blkno) и бројот на слободни бајти (avail) на секоја страница. При мали табели вредностите често се 0, но по масовно вметнување или бришење редови FSM покажува различни количини на слободен простор, што го потврдува начинoт на кој PostgreSQL ги користи и рециклира страниците.
- Visibility Map (VM) - датотека со суфикс _vm која означува кои страници (pages) немаат "мртви" записи (tuples што се избришани но сè уште физички постојат)
- Initialization Fork - датотека со суфикс _init која се користи само за unlogged табели и нивните индекси. Тоа е празна табела или индекс која автоматски заменува unlogged табела по системски пад.
Во PostgreSQL, секоја табела и индекс се чуваат во датотеки именувани според нивниот filenode. Кога големината на релацијата ќе надмине 1 GB, фајлот автоматски се дели на сегменти од по 1 GB. Првиот сегмент го задржува оригиналното име (filenode), додека следните сегменти се именуваат како filenode.1, filenode.2 итн.
Табелите кои што имаат колони со потенцијално големи вредности обиваат дополнителна TOAST табела (The Oversized-Attribute Storage Technique). Оваа табела се користи за складирање на полиња кои се преголеми за да се чуваат директно во редовите на главната табела. Врската меѓу главната табела и нејзината TOAST табела може да се најде во pg_class.reltoastrelid.
Тablespace овозможуваат PostgreSQL да ги складира податоците на различни физички локации, а не само во PGDATA. Секој кориснички tablespace има симболички линк во PGDATA/pg_tblspc/ кој упатува кон неговиот реален директориум и е именуван според неговиот OID. Во тој директориум PostgreSQL креира поддиректориуми според верзијата на серверот и според базата што го користи tablespace-от. Табелите и индексите се чуваат таму со истата filenode шема на именување.
Двата default tablespace-и, pg_default и pg_global, не се пристапуваат преку pg_tblspc. Наместо тоа pg_default соодветствува на PGDATA/base а pg_global соодветствува на PGDATA/global.
ИНДЕКСИ
Индексите се посебни структури на податоци кои го забрзуваат пребарувањето и пристапот до податоци во табелите. Без индекси, PostgreSQL мора да изврши последователно скенирање(sequential scan) на целата табела за да ги најде потребните редови. Со индекси, пребарувањето е значително побрзо, особено кај табели со голем број на редови.
Типови на индекси во PostgreSQL:
- B-tree - стандарден индекс, погоден за пребарување по еднаквост и опсег (=, <, >, <=, >=, BETWEEN)
- Hash - за едноставни споредби со (=)
- GiST - за геометриски податоци и full-text податоци. Нуди повеќе стратегии како nearest neighbor и делумно совпаѓање со пребарувањето.
- GIN (Generalized Inverted Index) - за колони со повеќевредносни податоци (JSONB, arrays, full-text search)
- BRIN (Block Range Index) - компактен индекс наменет за екстремно големи табели. Наместо да го индексира секој ред поединечно, ги групира редовите во блокови и чува сумарни информации за секој блок, што заштедува значителен простор на диск.
Креирањето индекси значително ги подобрува перформансите при SELECT операции и JOIN-операции, особено кај големи табели. Од друга страна, секое додавање на нов индекс го зголемува просторот на дискот и операциите како што се INSERT, UPDATE и DELETE стануваат по спори бидејќи индексите мора да се ажурираат заедно со табелата. Затоа, индексите треба да се креираат внимателно само на колони што навистина се користат во WHERE или JOIN операции.
Некој од најчестите прашалници за FilmRentalDB се:
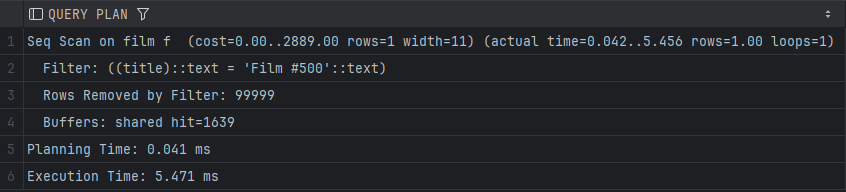
Пребарување на филмови по наслов
EXPLAIN ANALYSE SELECT f.title FROM film f WHERE f.title = 'Film #500';

PostgreSQL прави последователно скенирање на целата film табела, што значи дека мора да ги прочита сите редови за да го најде точниот наслов. Ова резултира со поголемо време за извршување, особено кај табела со голем број на редови.
По креирањето на индексот повторно го извршуваме истиот прашалник.
CREATE INDEX index_film_title ON film(title);

Додавањето индекс на колоната title значително ги подобри перформансите на пребарувањето. PostgreSQL повеќе не ја скенира целата табела, туку директно пристапува до точниот запис преку индексот.
Пребарување на клиенти по презиме
EXPLAIN ANALYSE SELECT * FROM customer WHERE last_name = 'Lastname320';

CREATE INDEX index_customer_lastname ON customer(last_name);

Пребарување на филмови по категорија
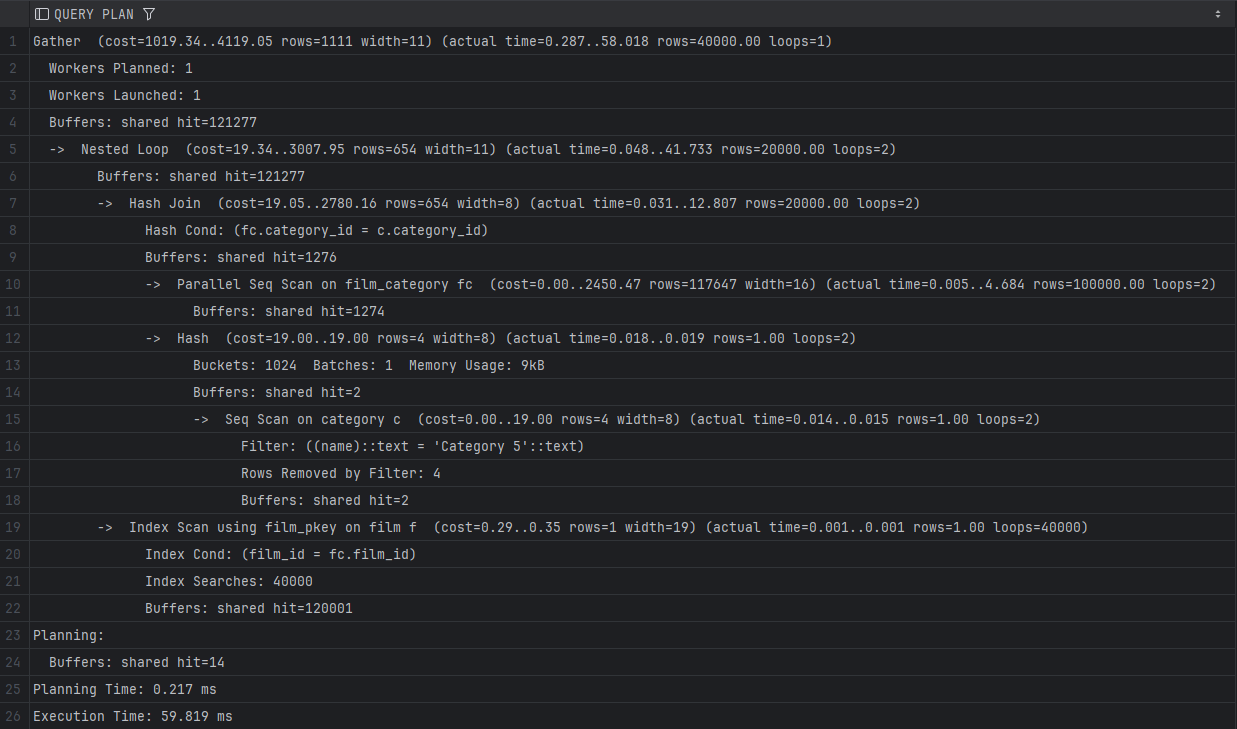
EXPLAIN ANALYSE SELECT f.title FROM film f JOIN film_category fc ON f.film_id = fc.film_id JOIN category c ON c.category_id = fc.category_id WHERE c.name = 'Category 5';

Овој прашалник бара поврзување на три табели. PostgreSQL извршуваше целосно скенирање на табелата film_category, и тоа како Parallel Seq Scan, што значи дека мора да ги прочита сите 200.000 редови за да го најде соодветниот category_id. Ова резултираше со време на извршување од околу 59 ms.
Додавање на индекси.
CREATE INDEX idx_category_name ON category(name); CREATE INDEX idx_film_category_category_id ON film_category(category_id); CREATE INDEX idx_film_category_film_id ON film_category(film_id);

По додавањето на индексите PostgreSQL започна да користи Bitmap Index Scan, кој многу поефикасно ги лоцира сите редови што припаѓаат на Category 5 и чита само релевантни страници од дискот. Времето на извршување се намали на 34 ms, што претставува значително подобрување.
Историја на изнајмување на клиент сортирана според датум
EXPLAIN ANALYSE
SELECT
c.first_name,
c.last_name,
f.title,
r.rental_date,
r.return_date
FROM customer c
JOIN rental r ON c.customer_id = r.customer_id
JOIN inventory i ON r.inventory_id = i.inventory_id
JOIN film f ON i.film_id = f.film_id
WHERE c.customer_id = 100
ORDER BY r.rental_date DESC;

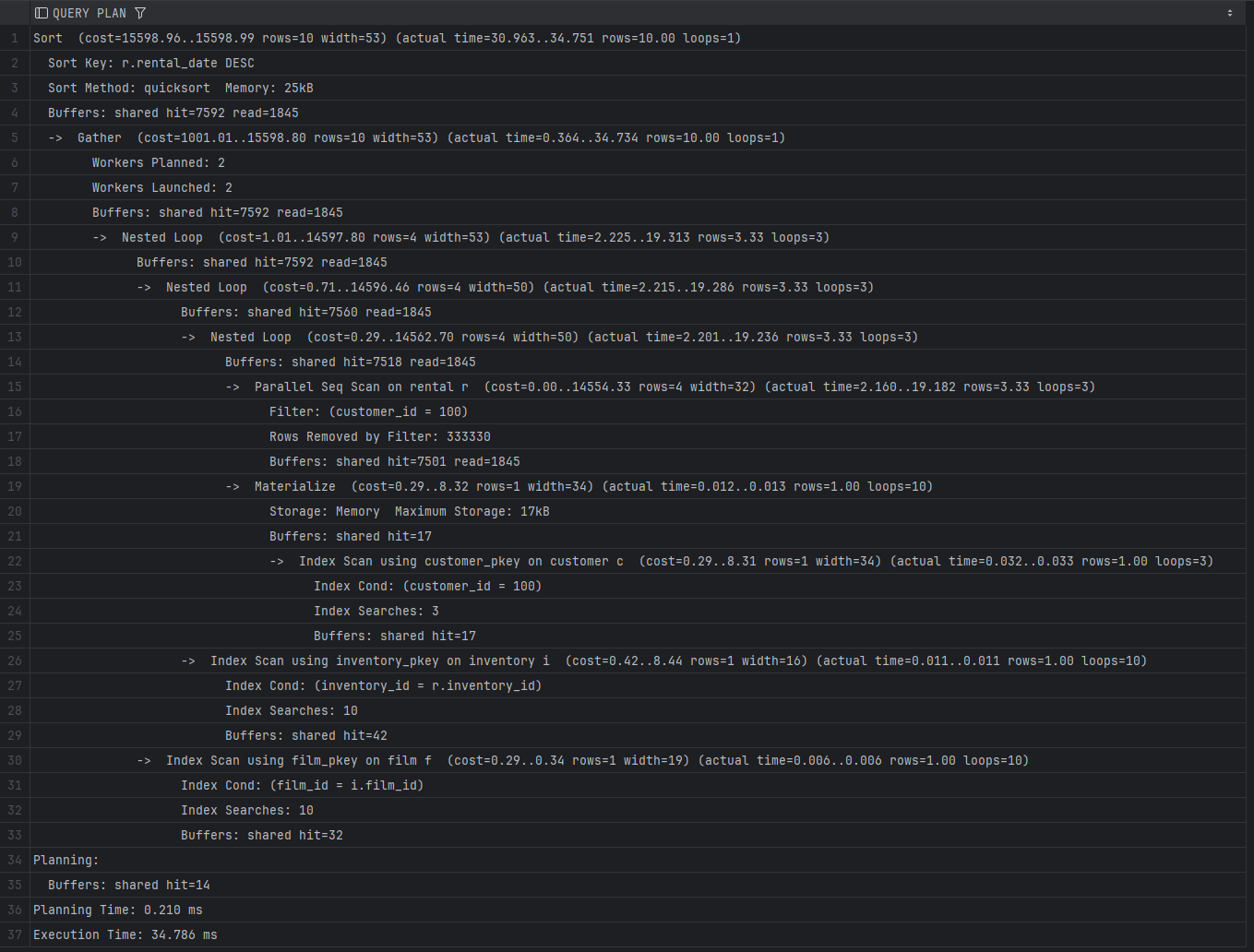
Пред додавање индекси, PostgreSQL правеше Parallel Sequential Scan на табелата rental и ги скенираше сите 300.000 редови за да ги најде само 10 што припаѓаат на клиентот со ID = 100. Целосното скенирање, филтрирање и финалното сортирање резултираше со време на извршување од 34.78 ms.
CREATE INDEX index_rental_customer_date ON rental(customer_id, rental_date DESC);

PostgreSQL веднаш ги лоцира само релевантните записи преку Index Scan, без потреба од сортирање (податоците се веќе сортирани во индексот). Новото време на извршување е само 0.334 ms што е многу побрзо од извршување без индекс.
Attachments (12)
- data_directory.png (4.9 KB ) - added by 7 months ago.
- oid_db.png (2.3 KB ) - added by 7 months ago.
- filenode_actor.png (2.6 KB ) - added by 7 months ago.
- free_space_map.png (8.5 KB ) - added by 7 months ago.
- query1_result.png (24.1 KB ) - added by 7 months ago.
- query1_result_index.png (29.7 KB ) - added by 7 months ago.
- query2_result.png (25.0 KB ) - added by 7 months ago.
- query2_result_index.png (29.9 KB ) - added by 7 months ago.
- query3_result.png (111.1 KB ) - added by 7 months ago.
- query3_result_index.png (77.2 KB ) - added by 7 months ago.
- query4_result.png (164.8 KB ) - added by 7 months ago.
- query4_result_index.png (124.5 KB ) - added by 7 months ago.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Download all attachments as: .zip