| Version 6 (modified by , 3 months ago) ( diff ) |
|---|
Оптимизација на прашалници и погледи
Во оваа фаза ќе ги анализираме погледите дефинирани во Фаза 2 преку прашалници базирани на реални сценарија кои ќе бидат присутни во нашата апликација и истите ќе се обидеме да ги оптимизираме.
1. Анализа на поглед 1, добивање на бројот на следбеници и бројот на профили кои ги следи даден корисник
Прашалниците кои ќе ги тестираме се следните:
-- 1A: информации за конкретен корисник SELECT * FROM user_follow_info WHERE user_id = 5; -- 1B: топ 10 најследени корисници SELECT * FROM user_follow_info ORDER BY followers DESC LIMIT 10;
Време на извршување без индекси:
1A - 18.639 ms
Nested Loop Left Join (cost=0.84..2007.41 rows=1 width=41) (actual time=18.370..18.375 rows=1 loops=1)
-> Nested Loop Left Join (cost=0.42..1998.96 rows=1 width=24) (actual time=16.163..16.167 rows=1 loops=1)
-> GroupAggregate (cost=0.42..8.45 rows=1 width=16) (actual time=0.099..0.101 rows=1 loops=1)
-> Index Only Scan using follows_follower_user_id_followed_user_id_key on follows (cost=0.42..8.44 rows=1 width=16) (actual time=0.090..0.093 rows=1 loops=1)
Index Cond: (follower_user_id = 5)
Heap Fetches: 1
-> GroupAggregate (cost=0.00..1990.49 rows=1 width=16) (actual time=16.060..16.061 rows=1 loops=1)
-> Seq Scan on follows follows_1 (cost=0.00..1986.00 rows=1793 width=8) (actual time=0.073..15.916 rows=1727 loops=1)
Filter: (followed_user_id = 5)
Rows Removed by Filter: 98273
-> Index Scan using users_pkey on users u (cost=0.42..8.44 rows=1 width=25) (actual time=2.202..2.202 rows=1 loops=1)
Index Cond: (id = 5)
Planning Time: 2.882 ms
Execution Time: 18.639 ms
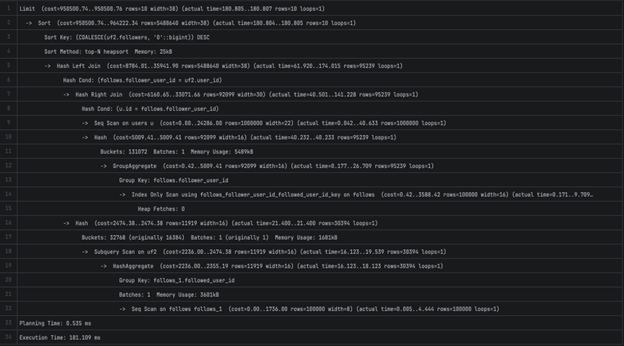
1B - 6055.326 ms
Limit (cost=193416.23..193416.26 rows=10 width=41) (actual time=6013.127..6013.139 rows=10 loops=1)
-> Sort (cost=193416.23..207558.87 rows=5657054 width=41) (actual time=5995.646..5995.657 rows=10 loops=1)
Sort Key: (COALESCE(uf2.followers, '0'::bigint)) DESC
Sort Method: top-N heapsort Memory: 25kB
-> Hash Left Join (cost=17633.85..71169.33 rows=5657054 width=41) (actual time=1875.103..5973.746 rows=95177 loops=1)
Hash Cond: (follows.follower_user_id = uf2.user_id)
-> Hash Right Join (cost=9034.90..60811.91 rows=92693 width=33) (actual time=1798.455..5836.973 rows=95177 loops=1)
Hash Cond: (u.id = follows.follower_user_id)
-> Seq Scan on users u (cost=0.00..35027.00 rows=1000000 width=25) (actual time=1598.256..4992.144 rows=1000000 loops=1)
-> Hash (cost=7423.24..7423.24 rows=92693 width=16) (actual time=200.143..200.146 rows=95177 loops=1)
Buckets: 16384 Batches: 16 Memory Usage: 407kB
-> GroupAggregate (cost=0.42..7423.24 rows=92693 width=16) (actual time=0.180..164.602 rows=95177 loops=1)
Group Key: follows.follower_user_id
-> Index Only Scan using follows_follower_user_id_followed_user_id_key on follows (cost=0.42..5996.31 rows=100000 width=16) (actual time=0.134..130.406 rows=100000 loops=1)
Heap Fetches: 100000
-> Hash (cost=8386.37..8386.37 rows=12206 width=16) (actual time=76.356..76.358 rows=30563 loops=1)
Buckets: 16384 (originally 16384) Batches: 4 (originally 2) Memory Usage: 480kB
-> Subquery Scan on uf2 (cost=7361.00..8386.37 rows=12206 width=16) (actual time=43.415..66.845 rows=30563 loops=1)
-> HashAggregate (cost=7361.00..8264.31 rows=12206 width=16) (actual time=43.406..64.059 rows=30563 loops=1)
Group Key: follows_1.followed_user_id
Planned Partitions: 4 Batches: 21 Memory Usage: 601kB Disk Usage: 824kB
-> Seq Scan on follows follows_1 (cost=0.00..1736.00 rows=100000 width=8) (actual time=0.022..11.332 rows=100000 loops=1)
Planning Time: 1.715 ms
Execution Time: 6055.326 ms
Веќе постои индекс на (follower_user_id, followed_user_id) поради unique constraint во ddl-от, па follower_user_id може да се земе од таму, но за да се земе followed_user_id мора да се скенира табелата секвенцијално. Затоа, го додаваме следниот индекс:
CREATE INDEX idx_follows_followed_user_id ON follows(followed_user_id);
Време на извршување со индекс:
1A — 3.993 ms (беше 18.639 ms)
Nested Loop Left Join (cost=27.03..806.01 rows=1 width=41) (actual time=3.702..3.704 rows=1 loops=1)
-> Nested Loop Left Join (cost=26.61..797.56 rows=1 width=24) (actual time=3.683..3.685 rows=1 loops=1)
-> GroupAggregate (cost=0.42..8.45 rows=1 width=16) (actual time=0.097..0.098 rows=1 loops=1)
-> Index Only Scan using follows_follower_user_id_followed_user_id_key on follows (cost=0.42..8.44 rows=1 width=16) (actual time=0.088..0.090 rows=1 loops=1)
Index Cond: (follower_user_id = 5)
Heap Fetches: 1
-> GroupAggregate (cost=26.19..789.09 rows=1 width=16) (actual time=3.582..3.583 rows=1 loops=1)
-> Bitmap Heap Scan on follows follows_1 (cost=26.19..784.60 rows=1793 width=8) (actual time=0.363..3.396 rows=1727 loops=1)
Recheck Cond: (followed_user_id = 5)
Heap Blocks: exact=666
-> Bitmap Index Scan on idx_follows_followed_user_id (cost=0.00..25.74 rows=1793 width=0) (actual time=0.255..0.255 rows=1727 loops=1)
Index Cond: (followed_user_id = 5)
-> Index Scan using users_pkey on users u (cost=0.42..8.44 rows=1 width=25) (actual time=0.016..0.016 rows=1 loops=1)
Index Cond: (id = 5)
Planning Time: 2.325 ms
Execution Time: 3.993 ms
1B — 1158.681 ms (беше 6055.326 ms)
Limit (cost=190809.26..190809.28 rows=10 width=41) (actual time=1119.728..1119.739 rows=10 loops=1)
-> Sort (cost=190809.26..204951.89 rows=5657054 width=41) (actual time=1104.495..1104.505 rows=10 loops=1)
Sort Key: (COALESCE(uf2.followers, '0'::bigint)) DESC
Sort Method: top-N heapsort Memory: 25kB
-> Hash Left Join (cost=15026.87..68562.35 rows=5657054 width=41) (actual time=312.601..1083.510 rows=95177 loops=1)
Hash Cond: (follows.follower_user_id = uf2.user_id)
-> Hash Right Join (cost=9034.90..60811.91 rows=92693 width=33) (actual time=210.510..922.405 rows=95177 loops=1)
Hash Cond: (u.id = follows.follower_user_id)
-> Seq Scan on users u (cost=0.00..35027.00 rows=1000000 width=25) (actual time=62.089..259.973 rows=1000000 loops=1)
-> Hash (cost=7423.24..7423.24 rows=92693 width=16) (actual time=148.205..148.208 rows=95177 loops=1)
Buckets: 16384 Batches: 16 Memory Usage: 407kB
-> GroupAggregate (cost=0.42..7423.24 rows=92693 width=16) (actual time=0.140..116.621 rows=95177 loops=1)
Group Key: follows.follower_user_id
-> Index Only Scan using follows_follower_user_id_followed_user_id_key on follows (cost=0.42..5996.31 rows=100000 width=16) (actual time=0.094..83.835 rows=100000 loops=1)
Heap Fetches: 100000
-> Hash (cost=5779.40..5779.40 rows=12206 width=16) (actual time=101.825..101.827 rows=30563 loops=1)
Buckets: 16384 (originally 16384) Batches: 4 (originally 2) Memory Usage: 480kB
-> Subquery Scan on uf2 (cost=0.29..5779.40 rows=12206 width=16) (actual time=1.560..90.836 rows=30563 loops=1)
-> GroupAggregate (cost=0.29..5657.34 rows=12206 width=16) (actual time=1.552..87.771 rows=30563 loops=1)
Group Key: follows_1.followed_user_id
-> Index Only Scan using idx_follows_followed_user_id on follows follows_1 (cost=0.29..5035.28 rows=100000 width=8) (actual time=0.057..71.498 rows=100000 loops=1)
Heap Fetches: 100000
Planning Time: 1.857 ms
Execution Time: 1158.681 ms
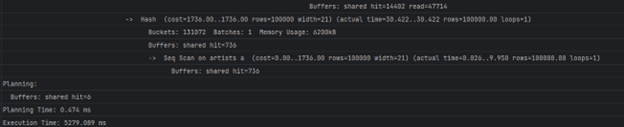
2. Анализа на поглед 2, најактивни корисници на платформата според бројот на слушања во изминатите 30 дена
Прашалниците кои ќе ги тестираме се следните:
-- 2A: активност на еден корисник SELECT * FROM user_activity_last_30_days WHERE user_id = 100376; -- 2B: топ 10 најактивни корисници SELECT * FROM user_activity_last_30_days ORDER BY stream_count DESC LIMIT 10;
Време на извршување без индекси:
2A — 389.404 ms
`
Nested Loop (cost=1000.42..128052.52 rows=1 width=33) (actual time=341.291..351.235 rows=1 loops=1)
-> Index Scan using users_pkey on users u (cost=0.42..8.44 rows=1 width=25) (actual time=0.760..0.764 rows=1 loops=1)
Index Cond: (id = 100376)
-> GroupAggregate (cost=1000.00..128044.07 rows=1 width=16) (actual time=340.519..350.456 rows=1 loops=1)
-> Gather (cost=1000.00..128044.06 rows=1 width=16) (actual time=137.273..350.389 rows=2 loops=1)
Workers Planned: 2 Workers Launched: 2 -> Parallel Seq Scan on song_streams ss (cost=0.00..127043.96 rows=1 width=16) (actual time=149.103..281.419 rows=1 loops=3)
Filter: ((user_id = 100376) AND (streamed_at <= now()) AND (streamed_at >= (CURRENT_DATE - 30))) Rows Removed by Filter: 2258560
Planning Time: 1.687 ms Execution Time: 389.404 ms
`
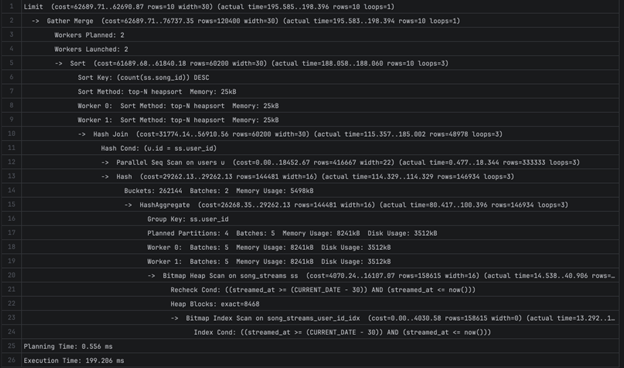
2B — 1976.733 ms
`
Limit (cost=193729.83..193814.38 rows=10 width=162) (actual time=1965.655..1965.803 rows=10 loops=1)
-> Result (cost=193729.83..5188284.34 rows=590722 width=162) (actual time=1953.440..1953.585 rows=10 loops=1)
-> Sort (cost=193729.83..195206.63 rows=590722 width=16) (actual time=1953.266..1953.270 rows=10 loops=1)
Sort Key: (count(ss.song_id)) DESC Sort Method: top-N heapsort Memory: 25kB -> HashAggregate (cost=165561.66..180964.54 rows=590722 width=16) (actual time=1326.637..1865.932 rows=593461 loops=1)
Group Key: ss.user_id Planned Partitions: 8 Batches: 9 Memory Usage: 8273kB Disk Usage: 31768kB -> Bitmap Heap Scan on song_streams ss (cost=24927.09..103270.10 rows=972356 width=16) (actual time=109.482..553.897 rows=970108 loops=1)
Recheck Cond: ((streamed_at >= (CURRENT_DATE - 30)) AND (streamed_at <= now())) Heap Blocks: exact=56465 -> Bitmap Index Scan on idx_song_streams_streamed_at_song_id (cost=0.00..24684.00 rows=972356 width=0) (actual time=95.352..95.353 rows=970108 loops=1)
Index Cond: ((streamed_at >= (CURRENT_DATE - 30)) AND (streamed_at <= now()))
SubPlan 1
-> Index Scan using users_pkey on users (cost=0.42..8.44 rows=1 width=17) (actual time=0.021..0.022 rows=1 loops=10)
Index Cond: (id = ss.user_id)
Planning Time: 0.476 ms JIT:
Functions: 24
" Options: Inlining false, Optimization false, Expressions true, Deforming true" " Timing: Generation 2.144 ms (Deform 0.808 ms), Inlining 0.000 ms, Optimization 1.505 ms, Emission 19.128 ms, Total 22.777 ms" Execution Time: 1976.733 ms
`
Бидејќи song_streams нема индекс на user_id, за прашалник 2А потребно е секвенцијално скенирање за да се најдат стримовите за еден корисник. Затоа, додаваме индекс на таа колона:
CREATE INDEX idx_song_streams_user_id ON song_streams(user_id);
Време за извршување по додавање на индекс
2A — 0.453 ms (was 389.404 ms)
Nested Loop (cost=0.86..45.14 rows=1 width=33) (actual time=0.295..0.297 rows=1 loops=1)
-> Index Scan using users_pkey on users u (cost=0.42..8.44 rows=1 width=25) (actual time=0.071..0.072 rows=1 loops=1)
Index Cond: (id = 100376)
-> GroupAggregate (cost=0.43..36.68 rows=1 width=16) (actual time=0.220..0.221 rows=1 loops=1)
-> Index Scan using idx_song_streams_user_id on song_streams ss (cost=0.43..36.67 rows=1 width=16) (actual time=0.089..0.214 rows=2 loops=1)
Index Cond: (user_id = 100376)
Filter: ((streamed_at <= now()) AND (streamed_at >= (CURRENT_DATE - 30)))
Rows Removed by Filter: 8
Planning Time: 1.843 ms
Execution Time: 0.453 ms
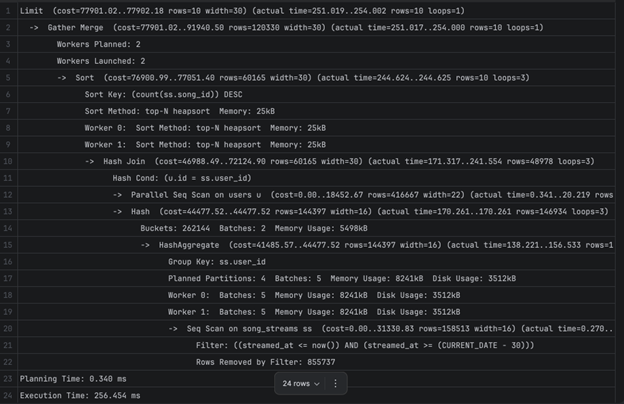
2Б остана непроменето - бидејќи прашалникот треба да направи комплексна агрегација на големи табели нема баш некој конкретен индекс што може да ги подобри перформансите. Доколку овој прашалник се извршува често во апликацијата, јасно е дека тоа може да доведе до проблеми. Ова можеме да го решиме на повеќе начини: со менување на погледот во материјализиран поглед, со кеширање и слично. Првиот пристап (материјализирани погледи) како решение ќе го погледнеме понатаму во оптимизацијата на други погледи, а конкретно за овој поглед ќе одиме со вториот пристап, поточно со кеширање во самиот апликациски код.
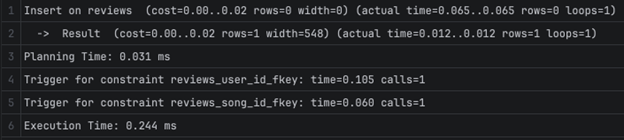
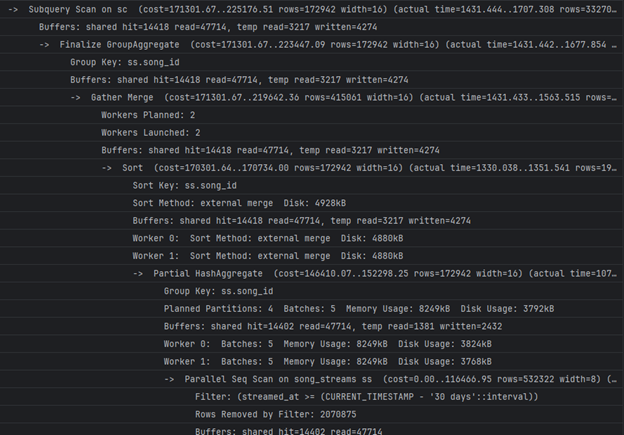
3. Анализа на поглед 3, рангирање на песни по нивните просечни оценки и бројот на вкупни оценки, соодветно
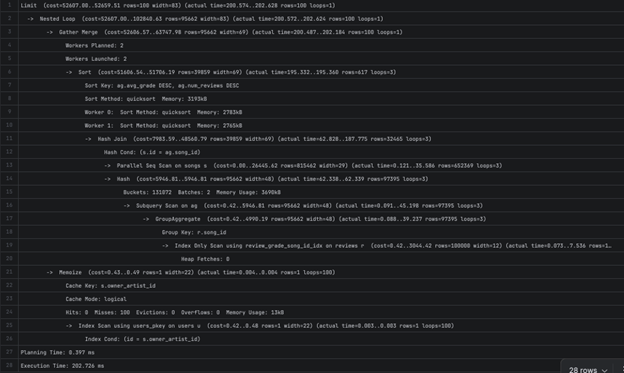
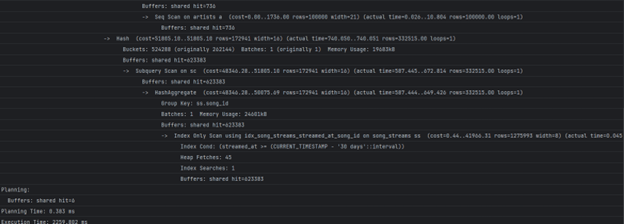
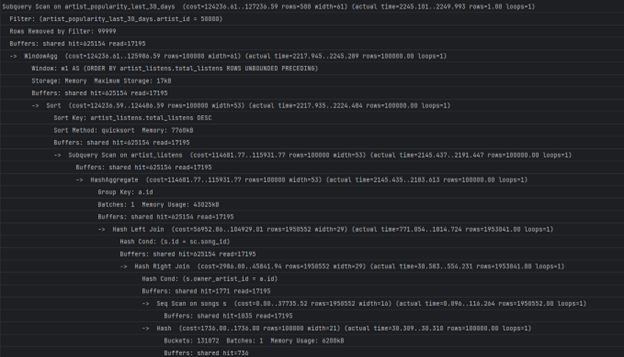
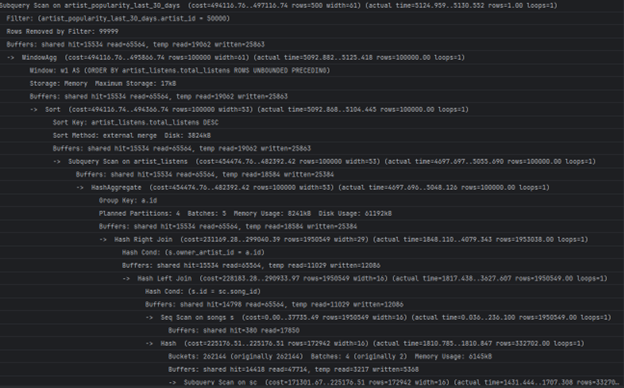
4. Анализа на поглед 4, рангирање на артистите по слушања (популарност) во изминатите 30 дена
- Доколку сакаме да видиме како одреден артист се рангира во споредба со остнатите артисти, извршуваме:

- Време потребно за пребарување:



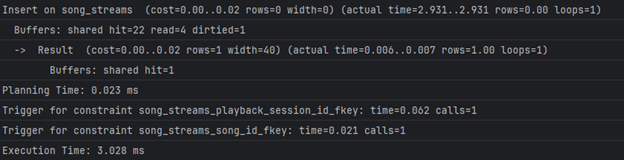
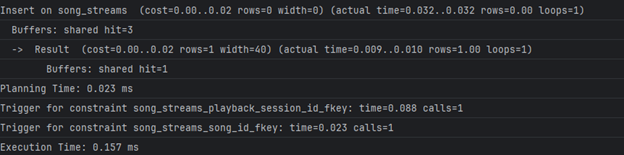
- ~5-6sec. Бавната операција е секвенцијално пребарување на Song_streams табелата што би можеле да го оптимизираме со индекс:

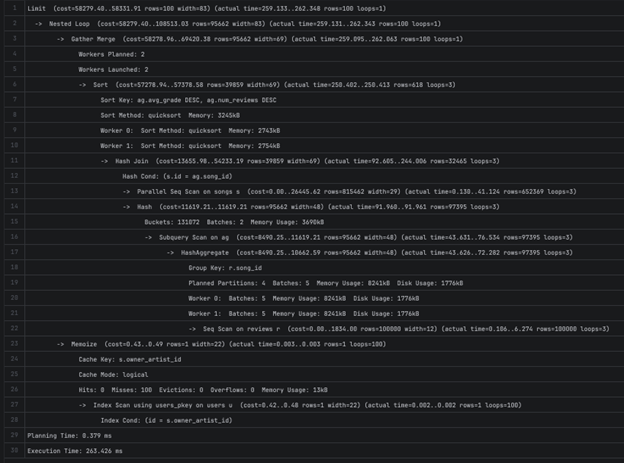
- Време на извршување со индекс:


- ~2sec. Со индекс добивме ~ 57% побрзо извршување.
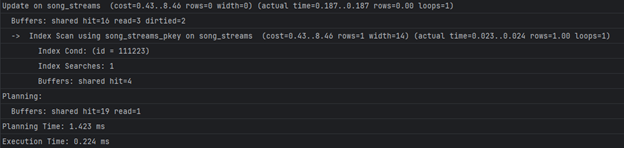
- Време потребно за внес на запис во Song_streams без индекс:


- 0.2ms
- Време потребно за внес на запис во Song_streams со индекс:

- ~3ms
- Време потребно за ажурирање запис во Song_streams без индекс:


- ~0.7ms
- Време потребно за ажурирање запис во Song_streams со индекс:

- ~0.2ms
Attachments (30)
- View1_1.png (14.9 KB ) - added by 3 months ago.
- View1_2.png (14.9 KB ) - added by 3 months ago.
- View1_3.png (82.2 KB ) - added by 3 months ago.
- View2_4.png (99.5 KB ) - added by 3 months ago.
- View2_3.png (13.4 KB ) - added by 3 months ago.
- View2_2.png (115.3 KB ) - added by 3 months ago.
- View2_1.png (14.5 KB ) - added by 3 months ago.
- View3_10.png (22.6 KB ) - added by 3 months ago.
- View3_9.png (22.8 KB ) - added by 3 months ago.
- View3_8.png (12.0 KB ) - added by 3 months ago.
- View3_7.png (42.1 KB ) - added by 3 months ago.
- View3_6.png (43.1 KB ) - added by 3 months ago.
- View3_5.png (25.0 KB ) - added by 3 months ago.
- View3_4.png (81.9 KB ) - added by 3 months ago.
- View3_3.png (13.6 KB ) - added by 3 months ago.
- View3_2.png (109.3 KB ) - added by 3 months ago.
- View3_1.png (14.9 KB ) - added by 3 months ago.
- View4_13.png (41.4 KB ) - added by 3 months ago.
- View4_12.png (34.1 KB ) - added by 3 months ago.
- View4_11.png (16.8 KB ) - added by 3 months ago.
- View4_10.png (64.9 KB ) - added by 3 months ago.
- View4_9.png (59.6 KB ) - added by 3 months ago.
- View4_8.png (27.7 KB ) - added by 3 months ago.
- View4_7.png (67.1 KB ) - added by 3 months ago.
- View4_6.png (135.2 KB ) - added by 3 months ago.
- View4_5.png (7.4 KB ) - added by 3 months ago.
- View4_4.png (33.9 KB ) - added by 3 months ago.
- View4_3.png (182.0 KB ) - added by 3 months ago.
- View4_2.png (174.4 KB ) - added by 3 months ago.
- View4_1.png (5.7 KB ) - added by 3 months ago.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Download all attachments as: .zip