| Version 13 (modified by , 6 days ago) ( diff ) |
|---|
Индексирање
Разликата помеѓу табела без индекси и правилно индексирана табела може да биде разликата помеѓу 5 секунди и 5 милисекунди за истата query. Ова не е само технички детал туку критичен фактор за корисничкото искуство и скалабилноста на системот. Во продолжение се наведени сценаријата во кои се употребувани индекси со соодветна причина за сегашната состојба на самата шема од табели.
НАПОМЕНА: Индексите се менуваат со промени на шемата и промени на употребата на истата.
1. Брзо пребарување при најава на апликацијата
Ова е едно од покористиените сценарија каде соодветно најавата на корисникот наложува проверка за негово постоење, кое се врши преку прецизна споредба со email адресата.
Доколку би имале гооолем број корисници, ќе треба некако да се пребаруваат побрзо корисниците за да може најавата да се одвива без многу чекање. Затоа, ќе поставиме индекс за лесно пребарување по email. Овој е BTREE индекс и е доста погоден за конкретни пребарувања (where email = :param)
Напомена: Login акцијата оди преку email, бидејќи истиот е поставен како уникатен, и 1 електронска адреса може да припаѓа на само 1 корисник во базата.
-- Појаснување:креира индекс со назив idx_user_email на табелата reportiumuser за колоната email CREATE INDEX IF NOT EXISTS idx_user_email ON reportiumuser (email);
За да се провери кога би имало многу податоци:
EXPLAIN (ANALYZE, BUFFERS) SELECT password_hash FROM reportiumuser WHERE email = :parameter_email ;
2. Ефикасно и ефективно сортирање по created_at за Report
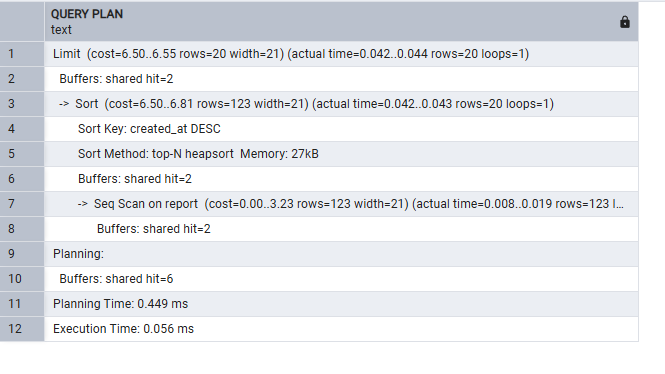
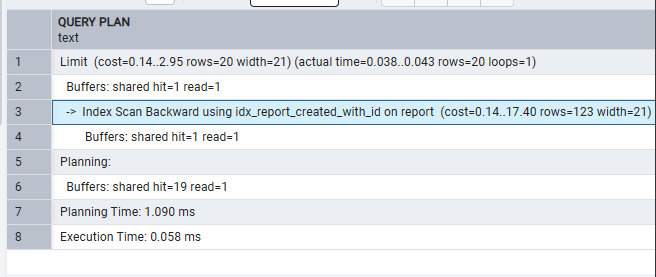
Многу важно е сортирањето по датумот кога е креиран некој извештај да биде ефикасно и ефективно исто-времено. За да постигнеме таква состојба, воведуваме индексирање, каде додаваме и соодветен tiebreaker, кој игра улога во случај 2 записи да имаат ист датум на креирањем, тогаш сортирањето се одвива според report_id кое е уникатно во самата табела..
-- се креира индекс со име idx_report_created_with_id врз Report табелата кој ги зема во обзир колоните created_at и report_id CREATE INDEX idx_report_created_with_id ON report (created_at, report_id);
Ова би овозможило сортирањето да е брзо и ефикасно кога во апликацијата би се ракувало со масовна бројка на Report записи.
За тестирање:
EXPLAIN (ANALYZE, BUFFERS) SELECT report_id, report_type, person_id, summary FROM report ORDER BY created_at, report_id LIMIT 20;
или
EXPLAIN (ANALYZE, BUFFERS) SELECT report_id, report_type, person_id, summary FROM report ORDER BY created_at DESC, report_id DESC LIMIT 20;
Фотографии кои покажуваат некаква позитивна промена на само 100тина записи, а скалабилно ако го зголемиме бројот на записи, би добиле значително пократко време на сортирање.
Пред индексирањето

После индексирањето

3. Статистика за топ 3 најдобри институции во изминатите години
Кверито кое успорува со многу податоци е следното:
-- EXPLAIN (ANALYZE, BUFFERS)
WITH top_3_institutions AS (
SELECT ar.institution_id, COUNT(*) AS total_reports
FROM report r
JOIN academicreport ar ON ar.report_id = r.report_id
WHERE r.created_at >= date_trunc('year', now()) - interval '1 year'
GROUP BY ar.institution_id
ORDER BY COUNT(*) DESC
LIMIT 3
)
SELECT i.name, a.total_reports
FROM top_3_institutions a
JOIN institution i ON i.institution_id = a.institution_id
ORDER BY a.total_reports DESC;
Ова квери се користи во функција во апликацијата, каде функционалноста е реализирана во панелот на корисникот и се прикажува како статистика „најдобрите 3 институции во изминатата 1 година во кои се издавале академски извештаи по вкупниот број на извештаи“.
Прво прави секвенцијални пребарувања на report, потоа на academicreport и на крај прави на institution. Со ова ги наоѓа табелите. Потоа почнува со Hash Joins (спојувања join операции) и HashAggregate (group by операции), и како за крај прави сортирање (Sort) и тоа по функција count(*) (по бројот на записи). Ова би било доста спора операција во случај на многу записи низ кои треба да бара, што совршено би се решило со поставување на неколку индекси:
-- Овој индекс овозможува побрзо филтрирање по датум (created_at), со цел да спречи скенирање на целата табела, туку само последната година. CREATE INDEX IF NOT EXISTS ix_report_created_at ON report(created_at); -- Овој индекс ја забрзува join операцијата меѓу academicreport и report, бидејќи пребарувањето по report_id станува директно преку индекс. CREATE INDEX IF NOT EXISTS ix_ar_report_id ON academicreport(report_id); -- Овој индекс помага при групирање и пребројување по institution_id, а исто така и при join со institution табелата. CREATE INDEX IF NOT EXISTS ix_ar_institution_id ON academicreport(institution_id);
4. Пронаоѓање на слични дијагнози со селектиран пациент
Query кое се извршува со секое вклучување на панелот на пациентот:
EXPLAIN (ANALYZE, BUFFERS) with selected_person_diagnosis as( select distinct d.diagnosis_id as diagnosis_id, d.short_description as label from person p join report r on r.person_id = p.person_id join medicalreport_diagnosis mrd on mrd.report_id = r.report_id join diagnosis d on mrd.diagnosis_id = d.diagnosis_id where p.person_id = :person_id ) select cast(p2.person_id as bigint), p2.name || ' ' || p2.surname as full_name, cast(count(distinct spd.diagnosis_id) as bigint) as matching_diagnoses_count, string_agg(distinct spd.label, ', ') as matching_labels from selected_person_diagnosis spd join medicalreport_diagnosis mrd2 on mrd2.diagnosis_id = spd.diagnosis_id join report r2 on r2.report_id = mrd2.report_id join person p2 on p2.person_id = r2.person_id where p2.person_id != :person_id group by p2.person_id, p2.name, p2.surname having count(distinct spd.diagnosis_id) >=1 order by matching_diagnoses_count desc;
Тука имаме појава на многу операции (join, grouping, ordering). Истото ова квери кога би имало многу дијагнози и многу персони со многу медицински извештаи, може значително да го успори побарувањето. За да го превентираме истото, ќе додадеме некои едноставни но корисни индекси.
-- Индекс на табелата medicalreport_diagnosis што убрзува процесот на report->diagnosis пребарувања CREATE UNIQUE INDEX CONCURRENTLY IF NOT EXISTS ux_mrd_report_diagnosis ON medicalreport_diagnosis (report_id, diagnosis_id); -- Слично со горното, но во обратна насока CREATE INDEX CONCURRENTLY IF NOT EXISTS ix_mrd_diagnosis_report ON medicalreport_diagnosis (diagnosis_id, report_id); -- филтрирање на персони CREATE INDEX CONCURRENTLY IF NOT EXISTS ix_report_person ON report (person_id);
5. Напредно филтрирање
Овој процес на напредно филтрирање би бил многу заморен за базата кога би имало премногу податоци низ кои мора да помине. Затоа ќе воведеме соодветно индекси на клучните колони (оние кои се изложени на најголемо употребување) Оваа функционалност е дел од листањето на Report објекти, каде е назначена како Advanced Filtering. Исто така во оваа секција може да забележите појава на т.н gin index. Неговата примена е голема кога има целосно пребарување на текст.
-- поради филтрирањето по Person атрибутот CREATE INDEX CONCURRENTLY IF NOT EXISTS ix_report_person ON report (person_id); -- индекси за забрзување на спојувањата на табелите во функционалноста на „Напредно филтрирање“, на страна на Reports CREATE INDEX CONCURRENTLY IF NOT EXISTS ix_employment_report_fk ON employment_report (report_id); CREATE INDEX CONCURRENTLY IF NOT EXISTS ix_academic_report_fk ON academic_report (report_id); CREATE INDEX CONCURRENTLY IF NOT EXISTS ix_medical_report_fk ON medical_report (report_id); CREATE INDEX CONCURRENTLY IF NOT EXISTS ix_criminal_report_fk ON criminal_report (report_id); CREATE INDEX CONCURRENTLY IF NOT EXISTS ix_punishment_fk_report ON punishment (report_id); -- за medicalreport_diagnosis поврзувањата индексите ги направив во 4та анализа -- чести join операции кои се користат CREATE INDEX CONCURRENTLY IF NOT EXISTS ix_medical_doctor_fk ON medical_report (doctor_id); CREATE INDEX CONCURRENTLY IF NOT EXISTS ix_academic_institution_fk ON academic_report (institution_id); CREATE INDEX CONCURRENTLY IF NOT EXISTS ix_criminal_crime_type_fk ON criminal_report (crime_type_id); -- за пребарување по %term% CREATE EXTENSION IF NOT EXISTS pg_trgm; -- често е користено во филтрирањето за Person и Doctor, пребарувањето по име или презиме CREATE INDEX CONCURRENTLY IF NOT EXISTS ix_person_name ON person USING gin (lower(name) gin_trgm_ops); CREATE INDEX CONCURRENTLY IF NOT EXISTS ix_person_surname ON person USING gin (lower(surname) gin_trgm_ops); CREATE INDEX CONCURRENTLY IF NOT EXISTS ix_doctor_name_trgm ON doctor USING gin (lower(name) gin_trgm_ops); CREATE INDEX CONCURRENTLY IF NOT EXISTS ix_doctor_surname_trgm ON doctor USING gin (lower(surname) gin_trgm_ops); -- во филтрирањето се користи често за да се пресмета години и ранг на Report кои припаѓаат на Person објекти кои се од - до некоја возраст, или точна возраст -- бидејќи е само за живи, затоа го условуваме кога индексот да биде активиран CREATE INDEX CONCURRENTLY IF NOT EXISTS ix_person_dob_aliveON person (date_of_birth) WHERE date_of_death IS NULL;
Attachments (2)
- before_indexing_2.png (45.7 KB ) - added by 7 days ago.
- after_indexing_2.png (32.6 KB ) - added by 7 days ago.
{kind=link}
{kind=link}
Download all attachments as: .zip