| Version 3 (modified by , 4 months ago) ( diff ) |
|---|
Кеширање на податоци
Shared_buffers е конфигурациски параметар во PostgreSQL кој одредува колкава меморија ќе биде алоцирана за кеширање на податоци од базата. Оваа меморија се споделува меѓу сите PostgreSQL процеси и се користи за да се зачуваат често пристапувани страници од дискот директно во RAM меморијата. Целта е да се намали бројот на бавни дискови операции со тоа што податоците ќе бидат достапни директно од меморијата, што значително ги подобрува перформансите на базата. Кога корисникот бара податоци, PostgreSQL прво проверува дали тие се наоѓаат во shared_buffers, и само ако не се тука ќе чита од дискот. Правилното подесување на оваа вредност е критично за оптимални перформанси. Премногу мала вредност значи повеќе дискови операции, додека премногу голема може да предизвика проблеми со меморијата на системот.
Конфигурирање на shared_buffers
Конфигурирањето на shared_buffers се прави преку менување на postgresql.conf датотеката каде што се наоѓа параметарот shared_buffers (најчесто би требало да се наоѓа во /etc/postgresql/{version}/main/postgresql.conf). Општо препорачување е да се постави на околу 25% од вкупната RAM меморија на серверот, но не повеќе од 8GB за повеќето системи бидејќи PostgreSQL користи и оперативниот систем за кеширање (иако ова е сепак релативно, зависи од спецификациите на машината, зависи од потребите на системот итн. Особено кога базата си има цервер дедициран само за неа, shared_buffers може да бидат и повеќе од 25%, се разбира се додека не штети на останатиот дел од системот). На пример, ако имате 16GB RAM, можете да поставите shared_buffers = 4GB или shared_buffers = 4096MB. По промената на оваа вредност, потребно е да го рестартирате PostgreSQL серверот за промените да стапат на сила, бидејќи ова е параметар кој не може да се менува динамички. За помали системи со помалку од 1GB RAM, препорачува се да започнете со 128MB и постепено да ја зголемувате вредноста додека не забележите подобрување во перформансите. Важно е да се тестираат перформансите по секоја промена и да се следат системските ресурси за да се избегне преоптоварување на меморијата.
Друга опција за да се промени shared_buffers параметарот е преку конзола. Команда за да ја видите моменталната големина е: show shared_buffers;, а за да се промени е: alter system set shared_buffers to <desired_size>;
Дијагностика
- Shared buffers usage and hit ratio for individual queries:
SELECT query, shared_blks_hit + shared_blks_read AS total_shared_blocks_accessed, shared_blks_hit AS shared_hit, shared_blks_read AS shared_read, (shared_blks_hit::float / NULLIF(shared_blks_hit + shared_blks_read, 0)) * 100 AS hit_ratio, calls FROM pg_stat_statements ORDER BY total_shared_blocks_accessed DESC LIMIT 20;
- Shared buffers usage and hit ratio for indexes:
SELECT schemaname, relname AS table_name, indexrelname AS index_name, idx_blks_read, idx_blks_hit, CASE WHEN (idx_blks_hit + idx_blks_read) > 0 THEN idx_blks_hit::float / (idx_blks_hit + idx_blks_read) ELSE NULL END AS idx_hit_ratio FROM pg_statio_user_indexes WHERE (idx_blks_hit + idx_blks_read) > 10000 -- Only include indexes with substantial activity AND idx_blks_read > 1000 -- Ensure there are enough reads to make the ratio meaningful and schemaname != 'ingestion' ORDER BY idx_hit_ratio ASC, -- Worst ratios first idx_blks_read DESC -- For equal ratios, prioritize indexes with more disk reads LIMIT 200;
- Shared buffers hit ratio total (bez sum za individualno po tabela) - aim for 95-99%
SELECT sum(heap_blks_read) as heap_read, sum(heap_blks_hit) as heap_hit, sum(heap_blks_hit) / (sum(heap_blks_hit) + sum(heap_blks_read)) as ratio FROM pg_statio_user_tables;
- Кои табели и индекси се кеширани во shared_buffers и колку зафаќаат
CREATE EXTENSION IF NOT EXISTS pg_buffercache; --by tables/indexes SELECT c.relname AS relation, c.relkind AS type, count(*) AS buffers, round(count(*) * 8192.0 / (1024 * 1024), 2) AS size_mb FROM pg_buffercache b JOIN pg_class c ON b.relfilenode = pg_relation_filenode(c.oid) JOIN pg_database d ON b.reldatabase = d.oid WHERE d.datname = current_database() GROUP BY c.relname, c.relkind ORDER BY buffers DESC;
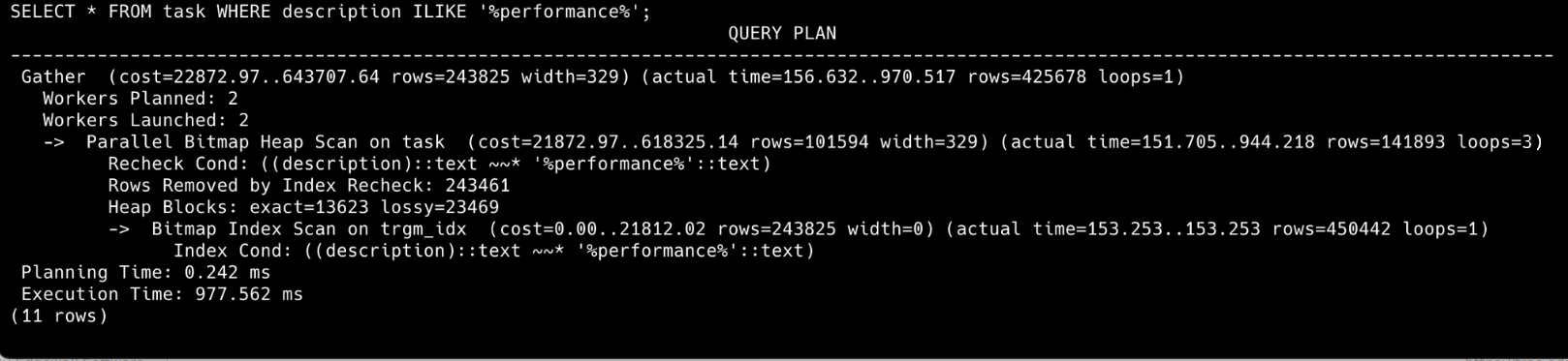
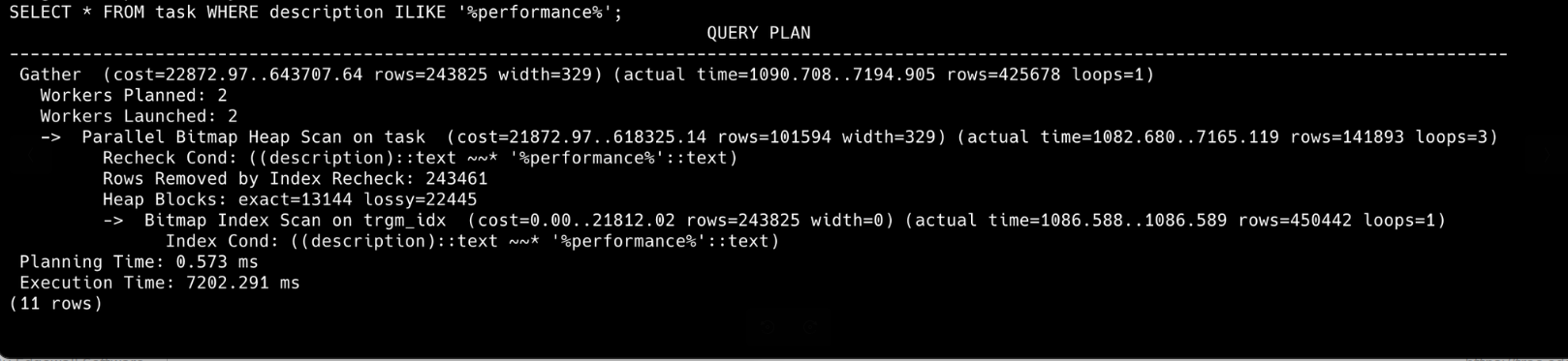
Тест
Тестот е изведен врз табелата task која е наполнета со 14.100.000 тест податоци. Тестовите се извршени еднаш со shared_buffers: 128MB еднаш со shared_buffers: 2GB.
Attachments (4)
- sb_desc_0_9.png (212.0 KB ) - added by 4 months ago.
- sb_1_2.png (219.8 KB ) - added by 4 months ago.
- sb_desc_7.png (207.2 KB ) - added by 4 months ago.
- sb_8_5.png (128.9 KB ) - added by 4 months ago.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Download all attachments as: .zip