Партиционирање на податоци
Партиционирање на податоците е техника каде што една табела се дели на повеќе помали физички делови наречени партиции. Секоја партиција е посебна табела што складира дел од вкупните податоци.
Главната цел на партиционирање на податоците е:
- Подобрување на перформансите при извршување на прашалници особено кога најчесто пристапуваните редови се наоѓаат во една или повеќе партиции. Исто така ги заменува по високите нивоа на индексите така што повеќе користените индекси се во меморија.
- Подобри перформанси за прашалници кои пристапуваат голем дел од една партиција со тоа што ќе се користи секвенцијално читање наместо индекси кој што ќе прават случајни читања низ целата табела.
- Голема ефикасност при масовно бришење и вчитување на податоци, со тоа што наместо да работиме ред по ред, можеме едноставно да додадеме или отстраниме цела партиција (користејќи ATTACH PARTITION или DROP TABLE/DETACH PARTITION ).
- Поефикасно искористување на дисковите за складирање на податоците со тоа што за податоците што ретко се пристапуваат може да се префрлат на поевтини дискови.
Во PostgreSQL постојат следниве вградени типови на партиционирање:
- Партиционирање по опсег(Range Partitioning) податоците се делат според опсег на вредности. Најчесто се користи за датуми, цени, возрасти и сл.
- Партиционирање по листа(List Partitioning) податоците се делат по однапред дефинирани вредности на одредена колона.
- Партиционирање по Хeш (Hash Partitioning) податоците се распределуваат рамномерно користејќи хеш функција. За секоја партиција се дефинира модулус/делител и остаток.
Партиционирањето е најкорисно за многу големи табели. Дали некоја табела би имала придобивка од партиционирање зависи од апликацијата. Ако табелата е релативно мала и ако нема јасен критериум за поделба тогаш партиционирањето може да донесе повеќе штета отколку корист. Во такви случаи се воведува дополнителна комплексност без значително подобрување на перформансите, а понекогаш и со нивно влошување.
Примена на партиционирање во FilmRentalDB
Во FilmRentalDB партиционирањето е најкорисно за табелите rental и payment поради тоа што тие може да содржат голем број на трансакции кои континуирано расте.
Партицинориање на rental табелата
Оваа табела ќе ја партиционираме по колоната rental_date со помош на Range партиционирање. Податоците ќе ги делиме по година со што ќе се овозможи побрзо пристапување до податоци во определен временски период.
За да ги направиме партициите прво ќе треба да ја преименуваме веќе постоечката rental табела се со цел да направиме нова партиционирана rental табела.
ALTER TABLE rental RENAME TO rental_old;
Потоа ја креираме новатa rental табела
CREATE TABLE rental (
rental_id BIGINT GENERATED ALWAYS AS IDENTITY,
rental_date TIMESTAMP NOT NULL,
inventory_id BIGINT NOT NULL,
customer_id BIGINT NOT NULL,
staff_id BIGINT NOT NULL,
return_date TIMESTAMP,
last_update TIMESTAMP DEFAULT now() NOT NULL,
PRIMARY KEY (rental_id, rental_date)
)
PARTITION BY RANGE (rental_date);
Тука rental_date мора да биде дел од примарниот клуч поради тоа што PostgreSQL бара колоната по која се партиционира да биде вклучена во сите UNIQUE ограничувања и примарни клучеви.
Во мојата база има 10 милиони записи движејќи се од 2020 до 2024 година. Па поради тоа правиме 5 партиции.
CREATE TABLE rental_2020 PARTITION OF rental
FOR VALUES FROM ('2020-01-01') TO ('2021-01-01');
CREATE TABLE rental_2021 PARTITION OF rental
FOR VALUES FROM ('2021-01-01') TO ('2022-01-01');
CREATE TABLE rental_2022 PARTITION OF rental
FOR VALUES FROM ('2022-01-01') TO ('2023-01-01');
CREATE TABLE rental_2023 PARTITION OF rental
FOR VALUES FROM ('2023-01-01') TO ('2024-01-01');
CREATE TABLE rental_2024 PARTITION OF rental
FOR VALUES FROM ('2024-01-01') TO ('2025-01-01');
Потоа ги внесуваме податоците од старата табела
INSERT INTO rental (rental_date, inventory_id, customer_id, staff_id, return_date, last_update) SELECT rental_date, inventory_id, customer_id, staff_id, return_date, last_update FROM rental_old;
На крај ги додаваме ограничувањата за надворешни клучеви.
ALTER TABLE rental ADD CONSTRAINT fk_rental_inventory FOREIGN KEY (inventory_id) REFERENCES inventory(inventory_id) ON UPDATE CASCADE ON DELETE RESTRICT; ALTER TABLE rental ADD CONSTRAINT fk_rental_customer FOREIGN KEY (customer_id) REFERENCES customer(customer_id) ON UPDATE CASCADE ON DELETE RESTRICT; ALTER TABLE rental ADD CONSTRAINT fk_rental_staff FOREIGN KEY (staff_id) REFERENCES staff(staff_id) ON UPDATE CASCADE ON DELETE RESTRICT;
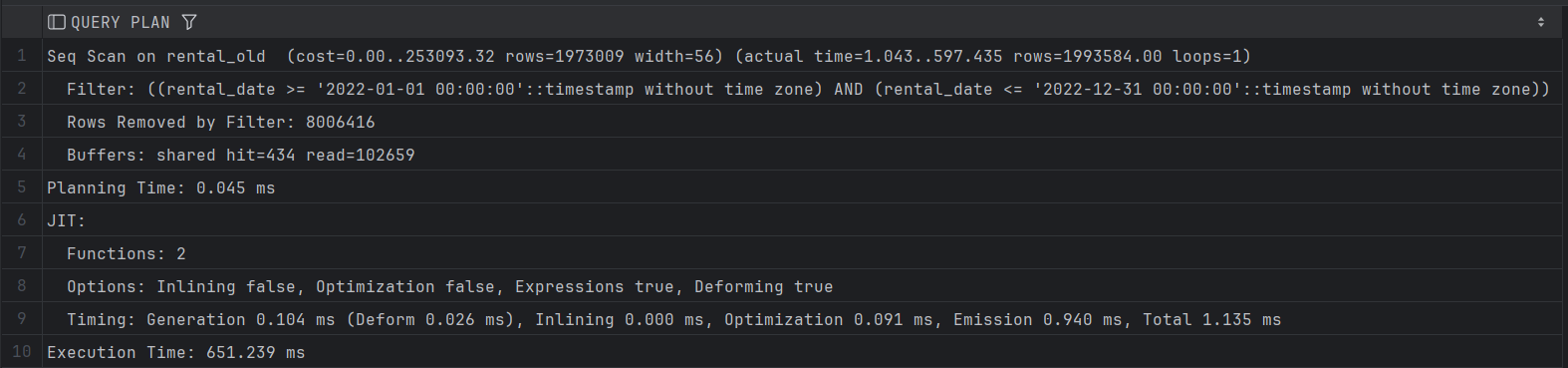
Сега ќе извршиме пример прашалник на старата табела(rental_old) каде што немаме партиции.
EXPLAIN ANALYSE SELECT * FROM rental_old WHERE rental_date >= '2022-01-01' AND rental_date <= '2022-12-31';

Од тука може да забележиме дека PostgreSQL мора да направи целосен Sequential Scan на табелата и бидејќи табелата не е партиционирана query optimizer-от нема да може да ги прескокне редовите што не припаѓаат на бараниот датумски опсег, па затоа ја скенира цела табела и елеминира повеќе од 8 милиони записи со помош на филтер.
Извршување на иситиот прашалник на новата партиционирана табела(rental).
EXPLAIN ANALYSE SELECT * FROM rental WHERE rental_date >= '2022-01-01' AND rental_date <= '2022-12-31';

По партиционирањето, PostgreSQL веќе не ја скенира целата табела, туку со помош на partition pruning кој што во поновите верзии на PostgreSQL е пуштен по default PostgreSQL не ги скенира партициите во кој што WHERE условот не е исполнет. Ја скенира само конкретната партиција rental_2022 и со тоа наместо да обработуваат 10 милиони редови, се обработуваат само податоците во релевантната партиција, времето на извршување е скоро преполовено и со помош на филтер се елиминираат околу 5 илјади редови наместо 8 милиони.
Партицинориање на payment табелата
Постапката е иста како и кај rental табелата.
ALTER TABLE payment RENAME TO payment_old;
CREATE TABLE payment (
payment_id BIGINT GENERATED ALWAYS AS IDENTITY,
customer_id BIGINT NOT NULL,
staff_id BIGINT NOT NULL,
rental_id BIGINT NOT NULL,
amount NUMERIC(5,2) NOT NULL,
payment_date TIMESTAMP NOT NULL,
PRIMARY KEY (payment_id, payment_date)
)
PARTITION BY RANGE (payment_date);
Тука правиме партиционирање по месец па така ќе имаме 5 години x 12 месеци = 60 партиции.
DO $$
DECLARE
y int;
m int;
start_date date;
end_date date;
partition_name text;
BEGIN
FOR y IN 2020..2024 LOOP
FOR m IN 1..12 LOOP
start_date := make_date(y, m, 1);
end_date := (make_date(y, m, 1) + interval '1 month')::date;
partition_name := format('payment_%s_%s', y, lpad(m::text, 2, '0'));
EXECUTE format(
'CREATE TABLE %I PARTITION OF payment
FOR VALUES FROM (%L) TO (%L);',
partition_name,
start_date,
end_date
);
END LOOP;
END LOOP;
END $$;
INSERT INTO payment (customer_id, staff_id, rental_id, amount, payment_date) SELECT customer_id, staff_id, rental_id, amount, payment_date FROM payment_old;
ALTER TABLE payment ADD CONSTRAINT fk_payment_customer FOREIGN KEY (customer_id) REFERENCES customer(customer_id) ON UPDATE CASCADE ON DELETE RESTRICT; ALTER TABLE payment ADD CONSTRAINT fk_payment_staff FOREIGN KEY (staff_id) REFERENCES staff(staff_id) ON UPDATE CASCADE ON DELETE RESTRICT;
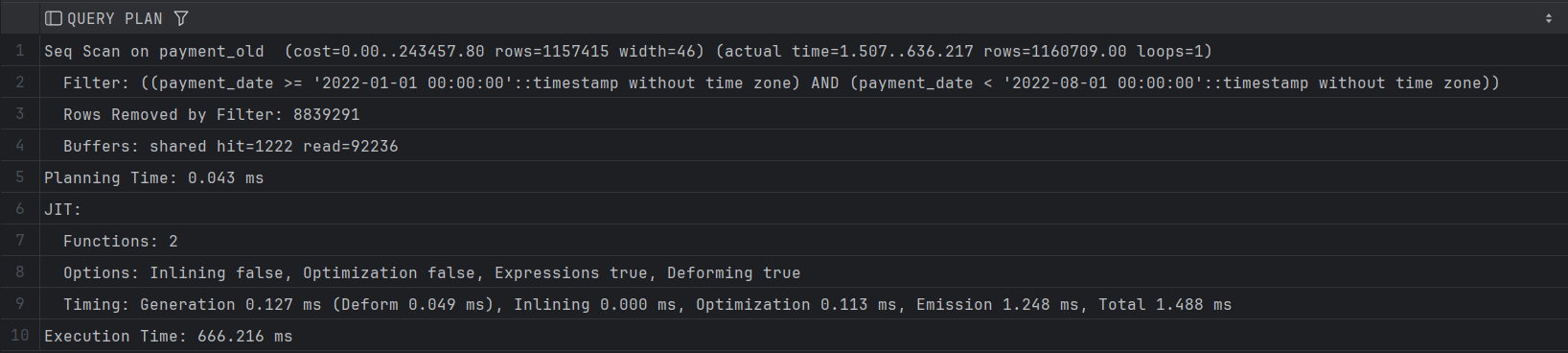
Извршување на прашалник на старата табела без партиции
EXPLAIN ANALYZE SELECT * FROM payment_old WHERE payment_date >= '2022-01-01' AND payment_date < '2022-08-01';

Извршување на прашалник на новата табела со партиции.
EXPLAIN ANALYSE SELECT * FROM payment WHERE payment_date >= '2022-01-01' AND payment_date < '2022-08-01';

PostgreSQL го корсити механизмот partition pruning така што наместо да ги скенира сите 60 партиции, ги скенира само они кои го опфаќаат периодот помеѓу 2022-01-01 и 2022-08-01, тоа се партициите payment_2022_01 до payment_2022_07.
Партицинориање на customer табелата
ALTER TABLE customer RENAME TO customer_old;
CREATE TABLE customer (
customer_id BIGINT GENERATED ALWAYS AS IDENTITY,
store_id INT NOT NULL,
first_name TEXT NOT NULL,
last_name TEXT NOT NULL,
email TEXT,
address_id BIGINT NOT NULL,
PRIMARY KEY (customer_id, store_id)
)
PARTITION BY LIST (store_id);
Сега ќе направиме партиционирање со List partitioning.
CREATE TABLE customer_store_1 PARTITION OF customer FOR VALUES IN (1); CREATE TABLE customer_store_2 PARTITION OF customer FOR VALUES IN (2); CREATE TABLE customer_store_3 PARTITION OF customer FOR VALUES IN (3); CREATE TABLE customer_store_4 PARTITION OF customer FOR VALUES IN (4); CREATE TABLE customer_store_5 PARTITION OF customer FOR VALUES IN (5);
INSERT INTO customer (store_id, first_name, last_name, email, address_id) SELECT store_id, first_name, last_name, email, address_id FROM customer_old;
ALTER TABLE customer ADD FOREIGN KEY (address_id) REFERENCES address(address_id); ALTER TABLE customer ADD FOREIGN KEY (store_id) REFERENCES store(store_id);
Извршување на прашалник на старата табела без партиции.
EXPLAIN ANALYSE SELECT * FROM customer_old WHERE store_id = 2;

PostgreSQL мора направи sequential scan и да елиминира 800 000 редови кои не припаѓаат на store_id = 2.
Извршување на прашалник на новата табела со партиции
EXPLAIN ANALYSE SELECT * FROM customer WHERE store_id = 2;

Со помош на механизмот pruning PostgreSQL ја скенира само customer_store_2 партицијата каде што store_id=2 и поради тоа се скенираат само 200 000 редови наместо 1 000 000 редови.
Attachments (6)
- rental_query.png (59.8 KB ) - added by 8 months ago.
- rental_query_partition.png (39.3 KB ) - added by 8 months ago.
- payment_query.png (59.0 KB ) - added by 8 months ago.
- payment_query_partition.png (188.3 KB ) - added by 8 months ago.
- customer_query.png (33.3 KB ) - added by 8 months ago.
- customer_query_partition.png (27.6 KB ) - added by 8 months ago.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Download all attachments as: .zip