| Version 20 (modified by , 4 months ago) ( diff ) |
|---|
Профилирање и оптимизација на извршувањето на прашалниците
Вовед
Airportdb има голем волумен на оперативни податоци (booking е најголема табела). Во production, кога паралелно се извршуваат OLTP операции (резервации/промени) и тешки аналитички прашалници, перформансите на базата стануваат тесно грло и влијаат врз корисничко искуство и стабилност. Целта на оваа фаза е да:
- идентификуваме slow queries што најчесто се извршуваат
- да ги анализираме со execution plan
- да примениме оптимизации (индекси/рефакторинг на SQL)
- и да измериме пред и потоа.
Поставување на бизнис барање:
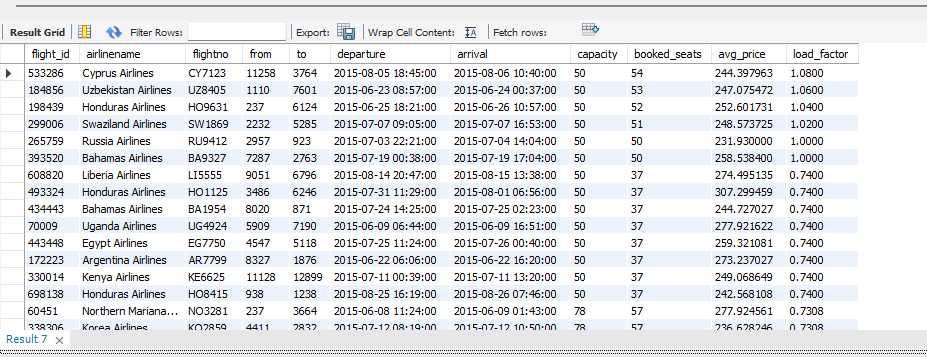
“За утрешниот ден, за секој лет да се прикаже: авиокомпанија, рута, време, капацитет на авион, број резервирани места, load factor (% пополнетост), и просечна цена по резервација. Да се филтрираат само летови што веќе имаат барем 1 резервација и сортирај по највисок load factor.”
Прашалник 1
SELECT
f.flight_id,
al.airlinename,
f.flightno,
f.`from`,
f.`to`,
f.departure,
f.arrival,
(SELECT a.capacity
FROM airplane a
WHERE a.airplane_id = f.airplane_id) AS capacity,
(SELECT COUNT(*)
FROM booking b
WHERE b.flight_id = f.flight_id) AS booked_seats,
(SELECT AVG(b2.price)
FROM booking b2
WHERE b2.flight_id = f.flight_id) AS avg_price,
(SELECT COUNT(*)
FROM booking b3
WHERE b3.flight_id = f.flight_id) /
(SELECT a2.capacity
FROM airplane a2
WHERE a2.airplane_id = f.airplane_id) AS load_factor
FROM flight f
JOIN airline al ON al.airline_id = f.airline_id
WHERE f.departure >= CURDATE()
AND f.departure < DATE_ADD(CURDATE(), INTERVAL 1 DAY)
AND (SELECT COUNT(*)
FROM booking bx
WHERE bx.flight_id = f.flight_id) > 0
ORDER BY load_factor DESC
LIMIT 100;


-> Limit: 100 row(s) (actual time=68039..68039 rows=100 loops=1)
-> Sort: load_factor DESC, limit input to 100 row(s) per chunk (actual time=68039..68039 rows=100 loops=1)
-> Stream results (cost=127262 rows=230643) (actual time=1.01..6782...
Од следните анализи може да се дојде до заклучок дека овој прашалник не е најоптимален поради тоа што correlated subqueries создаваат row-by-row извршување (nested loops) и повторено читање на истата табела, што е скапо кај големи datasets.
Ова прави повторување на COUNT/AVG над booking за секој flight ред.
- booking е огромна табела => ова може да стане N пати скенирање/индекс-скенирање.
- Двапати пресметуваме COUNT(*) (и уште еднаш во WHERE), што е уште полошо.
Оптимизација 1
Прво издвојуваме утрешни flight_id со CTE, па агрегираме само за нив.
WITH tomorrow_flights AS (
SELECT flight_id, airline_id, airplane_id, flightno, `from`, `to`, departure, arrival
FROM flight
WHERE departure >= CURDATE()
AND departure < DATE_ADD(CURDATE(), INTERVAL 1 DAY)
),
booking_x AS (
SELECT b.flight_id, COUNT(*) AS booked_seats, AVG(b.price) AS avg_price
FROM booking b
JOIN tomorrow_flights tf ON tf.flight_id = b.flight_id
GROUP BY b.flight_id
)
SELECT
tf.flight_id,
al.airlinename,
tf.flightno,
tf.`from`,
tf.`to`,
tf.departure,
tf.arrival,
a.capacity,
bx.booked_seats,
bx.avg_price,
bx.booked_seats / a.capacity AS load_factor
FROM tomorrow_flights tf
JOIN booking_x bx ON bx.flight_id = tf.flight_id
JOIN airline al ON al.airline_id = tf.airline_id
JOIN airplane a ON a.airplane_id = tf.airplane_id
ORDER BY load_factor DESC
LIMIT 100;
-> Limit: 100 row(s) (actual time=42155..42155 rows=100 loops=1)
-> Sort: load_factor DESC, limit input to 100 row(s) per chunk (actual time=42155..42155 rows=100 loops=1)
-> Stream results (cost=3.98e+6 rows=0) (actual time=39609..41987 r...
Зошто е многу побрзо?
- Избегнува повторувачки subquery-ја
- Користи CTE и JOIN наместо subqueries - го пресметува booked_seats и avg_price само еднаш преку GROUP BY, наместо за секој ред посебно.
- Филтрира порано - CTE tomorrow_flights ги филтрира летовите на почеток, па работи само со релевантни податоци.
- Помалку scan-ови на табелите - ги скенира booking & airplane само по еднаш.
- MySQL ги материјализира CTE-ата по default што значи дека резултатите се чуваат привремено и не се пресметуваат повторно.
Оптимизација 2 (Уште пооптимизирано)
Идеја: еднаш да агрегираме booking по flight_id (COUNT и AVG), па потоа само join-ираме.
SELECT
f.flight_id,
al.airlinename,
f.flightno,
f.`from`,
f.`to`,
f.departure,
f.arrival,
a.capacity,
bx.booked_seats,
bx.avg_price,
bx.booked_seats / a.capacity AS load_factor
FROM flight f
JOIN airline al ON al.airline_id = f.airline_id
JOIN airplane a ON a.airplane_id = f.airplane_id
JOIN (
SELECT
b.flight_id,
COUNT(*) AS booked_seats,
AVG(b.price) AS avg_price
FROM booking b
GROUP BY b.flight_id
) bx ON bx.flight_id = f.flight_id
WHERE f.departure >= CURDATE()
AND f.departure < DATE_ADD(CURDATE(), INTERVAL 1 DAY)
AND bx.booked_seats > 0
ORDER BY load_factor DESC
LIMIT 100;

-> Limit: 100 row(s) (actual time=20398..20398 rows=100 loops=1)
-> Sort: load_factor DESC, limit input to 100 row(s) per chunk (actual time=20398..20398 rows=100 loops=1)
-> Stream results (cost=10.3e+9 rows=103e+9) (actual time=18155..20...
Зошто е многу побрзо?
- booking се чита/групира еднаш, не повеќе пати по ред.
- Планот најчесто станува:
- booking -> aggregate by flight_id → мал резултат → join со flight, airplane, airline.
- Се намалува I/O и број на обработени редови.
Индекси
Индекси што исто така помагаат:
ALTER TABLE flight ADD INDEX ix_flight_departure (departure); - за да се филтрираат утрешните летови брзо ALTER TABLE booking ADD INDEX ix_booking_flight (flight_id); - за агрегирање по flight_id во booking ALTER TABLE booking ADD INDEX ix_booking_flight_price (flight_id, price); - ако бизнис барањата често налагаат пресметување на цената во просек или некои операции.
Attachments (3)
- F4 IMG 1.png (28.0 KB ) - added by 4 months ago.
- F4 IMG 2.png (47.2 KB ) - added by 4 months ago.
- F4 IMG 3.png (18.3 KB ) - added by 4 months ago.
{kind=link}
{kind=link}
{kind=link}
Download all attachments as: .zip