| Version 33 (modified by , 3 days ago) ( diff ) |
|---|
Други теми
Безбедност
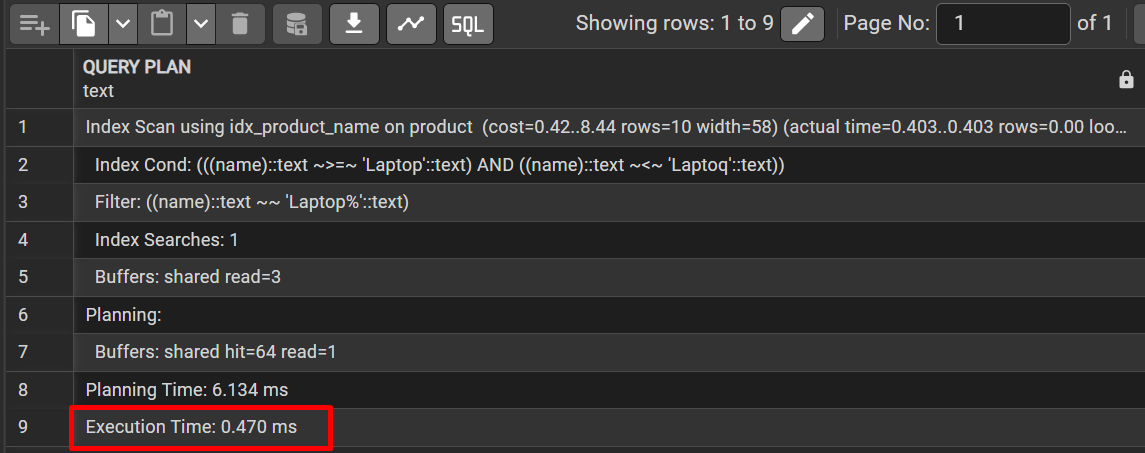
Спречување на SQL Injection
Користиме Entity Framework Core (ORM). EF Core автоматски ги параметризира сите LINQ прашања (queries). Ова спречува напаѓачите да вметнат злонамерни SQL команди преку полињата за внес.
- EF Core го третира username како параметар (@p0), а не како извршлив код.
- Ова спречува SQL Injection напади (на пр., ' OR 1=1 --).
public async Task<User> AuthenticateAsync(string username, string password)
{
var user = await _context.Users
.FirstOrDefaultAsync(u => u.Username == username && u.IsActive);
if (user == null)
return null;
bool isHashed = user.Password.StartsWith("$2") && user.Password.Length == 60;
if (isHashed)
{
if (BCrypt.Net.BCrypt.Verify(password, user.Password))
return user;
}
else
{
if (user.Password == password)
{
user.Password = BCrypt.Net.BCrypt.HashPassword(password);
await _context.SaveChangesAsync();
return user;
}
}
return null;
}
Хеширање на лозинки (Заштита на податоци)
Лозинките се зачувуваат како хеш вредности со користење на алгоритмот BCrypt, а не како обичен текст.
public async Task<bool> CreateUserAsync(User user, string password)
{
using var transaction = await _context.Database.BeginTransactionAsync();
try
{
user.Password = BCrypt.Net.BCrypt.HashPassword(password);
_context.Users.Add(user);
await _context.SaveChangesAsync();
await transaction.CommitAsync();
return true;
}
catch
{
await transaction.RollbackAsync();
return false;
}
}
Безбедност на Database Context (Row-Level идентификација)
Го пренесуваме идентитетот на моментално најавениот корисник од Application Layer до Database Layer (PostgreSQL) користејќи Session Variables. Ова и овозможува на базата на податоци да знае кој ја извршува операцијата.
public override async Task<int> SaveChangesAsync(CancellationToken cancellationToken = default)
{
var username = _httpContextAccessor.HttpContext?.User?.Identity?.Name ?? "system";
await Database.ExecuteSqlRawAsync("SELECT set_config('app.current_user', {0}, false)", new[] { username }, cancellationToken);
return await base.SaveChangesAsync(cancellationToken);
}
Авторизација (Role-Based Access Control)
Го ограничуваме пристапот до Controllers и Actions со користење на атрибутот [Authorize] . Само автентицирани корисници со валидни cookies можат да пристапат до овие ресурси.
- Овој атрибут осигурува дека само најавени корисници можат да пристапат до било која акција во овој контролер.
- Неавтентицираните барања се пренасочуваат кон страницата за најава (Login page).
using Microsoft.AspNetCore.Authorization;
using Microsoft.AspNetCore.Mvc;
namespace StockMaster.Controllers
{
[Authorize]
public class ReportController : Controller
{
private readonly IReportService _reportService;
public ReportController(IReportService reportService)
{
_reportService = reportService;
}
public IActionResult Index()
{
return View();
}
// ... други акции
}
}
Безбедност на база на податоци базирана на логика (Triggers)
Користиме Database Triggers за да спроведеме безбедносни правила што не можат да бидат заобиколени од апликацијата. Поточно, спречуваме корисник да ја избрише сопствената account за да обезбедиме стабилност на системот и следење на активности.
CREATE OR REPLACE FUNCTION stock_management.prevent_self_delete()
RETURNS TRIGGER AS $$
BEGIN
IF OLD.username = current_setting('app.current_user', true) THEN
RAISE EXCEPTION 'You cannot delete your own account.';
END IF;
RETURN OLD;
END;
$$ LANGUAGE plpgsql;
CREATE OR REPLACE TRIGGER trg_prevent_self_delete
BEFORE DELETE ON stock_management.users
FOR EACH ROW EXECUTE FUNCTION stock_management.prevent_self_delete();
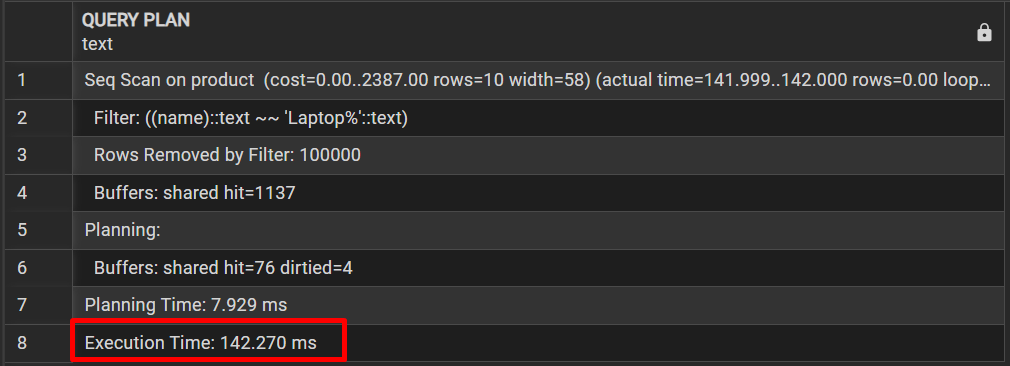
Пеформанси - Индекси
За да се зголеми перформансата на базата на податоци, се применуваат стратегии за индексирање и се анализира споредбата на перформансите во состојби со индекс и без индекс. Тестовите се извршени со користење на командата EXPLAIN ANALYZE за реални мерења во реално време.
Сценарио 1: Тековен залиха по складиште
Цел: Прикажува вкупниот број производи и вредност на залихата по складишта.Прашањето врши агрегација (SUM) на целата табела.
SELECT
w.warehouse_id,
w.name AS warehouse_name,
SUM(ws.quantity_on_hand) AS total_units,
SUM(ws.quantity_on_hand * p.unit_price) AS total_stock_value
FROM warehouse_stock ws
JOIN warehouse w ON ws.warehouse_id = w.warehouse_id
JOIN product p ON ws.product_id = p.product_id
GROUP BY w.warehouse_id, w.name
ORDER BY total_stock_value DESC;
1. Предложени индекси
За да се забрза пребарувањето и поврзувањето, предложен е индекс на надворешниот клуч во табелата warehouse_stock:
CREATE INDEX idx_wh_stock_product_id ON stock_management.warehouse_stock(product_id);
2. Анализа пред креирање на индексот (Без индекс)
EXPLAIN ANALYZE SELECT w.name, SUM(ws.quantity_on_hand), SUM(ws.quantity_on_hand * p.unit_price) FROM stock_management.warehouse_stock ws JOIN stock_management.warehouse w ON ws.warehouse_id = w.warehouse_id JOIN stock_management.product p ON ws.product_id = p.product_id GROUP BY w.warehouse_id, w.name;
"HashAggregate (cost=705.70..706.95 rows=100 width=262) (actual time=102.460..102.484 rows=3.00 loops=1)" " Group Key: w.warehouse_id" " Batches: 1 Memory Usage: 32kB" " Buffers: shared hit=164 dirtied=1" " -> Hash Join (cost=191.75..518.20 rows=15000 width=232) (actual time=4.965..78.081 rows=15000.00 loops=1)" " Hash Cond: (ws.product_id = p.product_id)" " Buffers: shared hit=164 dirtied=1" " -> Hash Join (cost=12.25..299.29 rows=15000 width=230) (actual time=0.282..37.808 rows=15000.00 loops=1)" " Hash Cond: (ws.warehouse_id = w.warehouse_id)" " Buffers: shared hit=97 dirtied=1" " -> Seq Scan on warehouse_stock ws (cost=0.00..246.00 rows=15000 width=12) (actual time=0.103..20.064 rows=15000.00 loops=1)" " Buffers: shared hit=96" " -> Hash (cost=11.00..11.00 rows=100 width=222) (actual time=0.068..0.069 rows=3.00 loops=1)" " Buckets: 1024 Batches: 1 Memory Usage: 9kB" " Buffers: shared hit=1 dirtied=1" " -> Seq Scan on warehouse w (cost=0.00..11.00 rows=100 width=222) (actual time=0.029..0.032 rows=3.00 loops=1)" " Buffers: shared hit=1 dirtied=1" " -> Hash (cost=117.00..117.00 rows=5000 width=10) (actual time=4.433..4.444 rows=5000.00 loops=1)" " Buckets: 8192 Batches: 1 Memory Usage: 279kB" " Buffers: shared hit=67" " -> Seq Scan on product p (cost=0.00..117.00 rows=5000 width=10) (actual time=0.044..1.930 rows=5000.00 loops=1)" " Buffers: shared hit=67" "Planning:" " Buffers: shared hit=86" "Planning Time: 26.724 ms" "Execution Time: 103.080 ms"
Времетраење: 103.080 ms
3. Анализа по креирање на индексот (Со индекс)
"HashAggregate (cost=705.70..706.95 rows=100 width=262) (actual time=29.541..29.548 rows=3.00 loops=1)" " Group Key: w.warehouse_id" " Batches: 1 Memory Usage: 32kB" " Buffers: shared hit=164" " -> Hash Join (cost=191.75..518.20 rows=15000 width=232) (actual time=2.793..18.549 rows=15000.00 loops=1)" " Hash Cond: (ws.product_id = p.product_id)" " Buffers: shared hit=164" " -> Hash Join (cost=12.25..299.29 rows=15000 width=230) (actual time=0.060..9.059 rows=15000.00 loops=1)" " Hash Cond: (ws.warehouse_id = w.warehouse_id)" " Buffers: shared hit=97" " -> Seq Scan on warehouse_stock ws (cost=0.00..246.00 rows=15000 width=12) (actual time=0.025..1.711 rows=15000.00 loops=1)" " Buffers: shared hit=96" " -> Hash (cost=11.00..11.00 rows=100 width=222) (actual time=0.019..0.021 rows=3.00 loops=1)" " Buckets: 1024 Batches: 1 Memory Usage: 9kB" " Buffers: shared hit=1" " -> Seq Scan on warehouse w (cost=0.00..11.00 rows=100 width=222) (actual time=0.011..0.013 rows=3.00 loops=1)" " Buffers: shared hit=1" " -> Hash (cost=117.00..117.00 rows=5000 width=10) (actual time=2.710..2.710 rows=5000.00 loops=1)" " Buckets: 8192 Batches: 1 Memory Usage: 279kB" " Buffers: shared hit=67" " -> Seq Scan on product p (cost=0.00..117.00 rows=5000 width=10) (actual time=0.010..1.133 rows=5000.00 loops=1)" " Buffers: shared hit=67" "Planning:" " Buffers: shared hit=12" "Planning Time: 0.761 ms" "Execution Time: 29.767 ms"
Времетраење: 29.767 ms
4. Дали индексот навистина се користи во планот за извршување?
Не. Доколку го анализираме планот за извршување (EXPLAIN PLAN) откако е креиран индексот, јасно се гледа дека PostgreSQL сè уште користи Seq Scan на warehouse_stock. Причината за ова е што барањето нема WHERE клаузула за филтрирање на специфични редови, тоа врши агрегација на сите податоци. За читање на 100% од редовите во една табела, Query Optimizer-от заклучува дека секвенцијалното скенирање е поефикасно од користењето на индекс.
5. Заклучок за перформансите
Иако времето на извршување се намали од ~103ms на ~29ms, ова не се должи на индексот. Ова е класичен пример за кеширање податоците биле вчитани во меморијата при првото извршување (shared hits), што го направило второто извршување побрзо. Индексот idx_wh_stock_product_id би бил корисен само доколку додадеме WHERE филтер за конкретен производ (на пр. WHERE ws.product_id = 5).
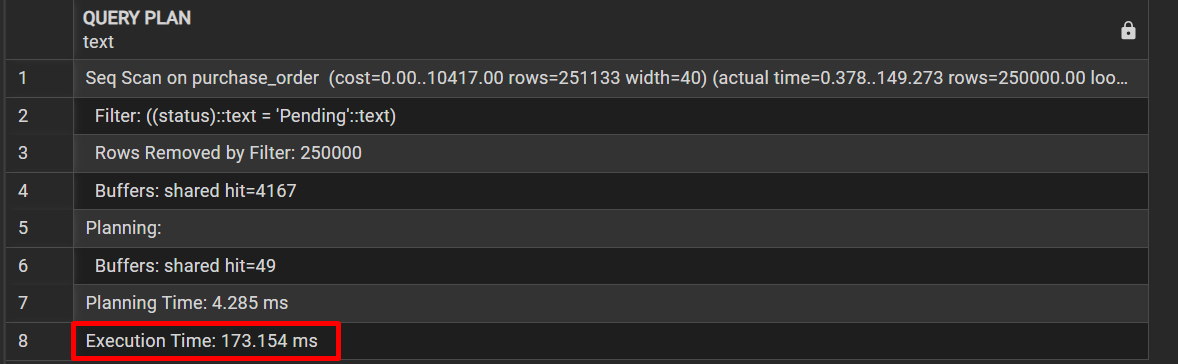
Сценарио 2: Годишен извештај за продажба (последни 12 месеци)
Цел: Прикажува детална анализа на продажбата за последните 12 месеци, групирана по месец, складиште, категорија и добавувач.
SELECT
TO_CHAR(date_trunc('month', s.date_time), 'YYYY-MM') AS sales_month,
w.name AS warehouse_name,
c.name AS category_name,
sup.name AS supplier_name,
COUNT(DISTINCT s.sale_id) AS total_order_count,
SUM(si.quantity) AS total_units_sold,
SUM(si.quantity * si.unit_price_at_sale) AS total_gross_revenue
FROM sale s
JOIN sale_item si ON s.sale_id = si.sale_id
JOIN product p ON si.product_id = p.product_id
LEFT JOIN category c ON p.category_id = c.category_id
LEFT JOIN supplier sup ON p.supplier_id = sup.supplier_id
JOIN warehouse w ON s.warehouse_id = w.warehouse_id
WHERE s.date_time >= date_trunc('month', CURRENT_DATE) - INTERVAL '11 months'
GROUP BY sales_month, w.name, c.name, sup.name
ORDER BY sales_month DESC, total_gross_revenue DESC;
1. Предложени индекси
За да се забрза филтрирањето на датумите и поврзувањето на табелите, предложени се следниве индекси:
CREATE INDEX idx_sale_date_time ON stock_management.sale(date_time DESC); CREATE INDEX idx_sale_warehouse_id ON stock_management.sale(warehouse_id); CREATE INDEX idx_product_supplier_id ON stock_management.product(supplier_id);
2. Анализа пред креирање на индексот (Без индекс)
EXPLAIN ANALYZE
SELECT
TO_CHAR(date_trunc('month', s.date_time), 'YYYY-MM') AS sales_month,
w.name AS warehouse_name,
c.name AS category_name,
sup.name AS supplier_name,
COUNT(DISTINCT s.sale_id) AS total_order_count,
SUM(si.quantity) AS total_units_sold,
SUM(si.quantity * si.unit_price_at_sale) AS total_gross_revenue
FROM sale s
JOIN sale_item si ON s.sale_id = si.sale_id
JOIN product p ON si.product_id = p.product_id
LEFT JOIN category c ON p.category_id = c.category_id
LEFT JOIN supplier sup ON p.supplier_id = sup.supplier_id
JOIN warehouse w ON s.warehouse_id = w.warehouse_id
WHERE s.date_time >= date_trunc('month', CURRENT_DATE) - INTERVAL '11 months'
GROUP BY sales_month, w.name, c.name, sup.name
ORDER BY sales_month DESC, total_gross_revenue DESC;
"Incremental Sort (cost=18709.65..51808.79 rows=139071 width=321) (actual time=2444.202..7628.612 rows=54435.00 loops=1)"
" Sort Key: (to_char(date_trunc('month'::text, s.date_time), 'YYYY-MM'::text)) DESC, (sum(((si.quantity)::numeric * si.unit_price_at_sale))) DESC"
" Presorted Key: (to_char(date_trunc('month'::text, s.date_time), 'YYYY-MM'::text))"
" Full-sort Groups: 12 Sort Method: quicksort Average Memory: 30kB Peak Memory: 30kB"
" Pre-sorted Groups: 12 Sort Method: quicksort Average Memory: 568kB Peak Memory: 615kB"
" Buffers: shared hit=3632, temp read=1176 written=1179"
" -> GroupAggregate (cost=18708.99..48041.17 rows=139071 width=321) (actual time=2116.416..7458.422 rows=54435.00 loops=1)"
" Group Key: (to_char(date_trunc('month'::text, s.date_time), 'YYYY-MM'::text)), w.name, c.name, sup.name"
" Buffers: shared hit=3632, temp read=1176 written=1179"
" -> Incremental Sort (cost=18708.99..42478.33 rows=139071 width=287) (actual time=2116.373..6967.664 rows=137806.00 loops=1)"
" Sort Key: (to_char(date_trunc('month'::text, s.date_time), 'YYYY-MM'::text)) DESC, w.name, c.name, sup.name, s.sale_id"
" Presorted Key: (to_char(date_trunc('month'::text, s.date_time), 'YYYY-MM'::text))"
" Full-sort Groups: 12 Sort Method: quicksort Average Memory: 30kB Peak Memory: 30kB"
" Pre-sorted Groups: 12 Sort Method: quicksort Average Memory: 1262kB Peak Memory: 1387kB"
" Buffers: shared hit=3632, temp read=1176 written=1179"
" -> Nested Loop (cost=18708.54..38710.70 rows=139071 width=287) (actual time=2093.902..2972.887 rows=137806.00 loops=1)"
" Buffers: shared hit=3632, temp read=1176 written=1179"
" -> Gather Merge (cost=18708.38..34558.39 rows=139071 width=49) (actual time=2093.791..2485.802 rows=137806.00 loops=1)"
" Workers Planned: 1"
" Workers Launched: 1"
" Buffers: shared hit=3626, temp read=1176 written=1179"
" -> Sort (cost=17708.37..17912.89 rows=81806 width=49) (actual time=1937.274..1979.269 rows=68903.00 loops=2)"
" Sort Key: (to_char(date_trunc('month'::text, s.date_time), 'YYYY-MM'::text)) DESC"
" Sort Method: external merge Disk: 3672kB"
" Buffers: shared hit=3626, temp read=1176 written=1179"
" Worker 0: Sort Method: external merge Disk: 5736kB"
" -> Hash Left Join (cost=3417.20..8236.54 rows=81806 width=49) (actual time=374.832..1517.447 rows=68903.00 loops=2)"
" Hash Cond: (p.supplier_id = sup.supplier_id)"
" Buffers: shared hit=3618"
" -> Hash Left Join (cost=3415.08..8001.47 rows=81806 width=41) (actual time=372.663..1142.797 rows=68903.00 loops=2)"
" Hash Cond: (p.category_id = c.category_id)"
" Buffers: shared hit=3616"
" -> Hash Join (cost=3412.95..7766.40 rows=81806 width=34) (actual time=368.131..1095.264 rows=68903.00 loops=2)"
" Hash Cond: (si.product_id = p.product_id)"
" Buffers: shared hit=3614"
" -> Parallel Hash Join (cost=3233.45..7371.99 rows=81806 width=30) (actual time=364.282..986.295 rows=68903.00 loops=2)"
" Hash Cond: (si.sale_id = s.sale_id)"
" Buffers: shared hit=3480"
" -> Parallel Seq Scan on sale_item si (cost=0.00..3675.36 rows=176436 width=18) (actual time=0.035..126.327 rows=149971.00 loops=2)"
" Buffers: shared hit=1911"
" -> Parallel Hash (cost=2892.53..2892.53 rows=27274 width=16) (actual time=358.216..358.220 rows=22972.00 loops=2)"
" Buckets: 65536 Batches: 1 Memory Usage: 2688kB"
" Buffers: shared hit=1569"
" -> Parallel Seq Scan on sale s (cost=0.00..2892.53 rows=27274 width=16) (actual time=1.149..298.091 rows=22972.00 loops=2)"
" Filter: (date_time >= (date_trunc('month'::text, (CURRENT_DATE)::timestamp with time zone) - '11 mons'::interval))"
" Rows Removed by Filter: 27028"
" Buffers: shared hit=1569"
" -> Hash (cost=117.00..117.00 rows=5000 width=12) (actual time=3.779..3.780 rows=5000.00 loops=2)"
" Buckets: 8192 Batches: 1 Memory Usage: 279kB"
" Buffers: shared hit=134"
" -> Seq Scan on product p (cost=0.00..117.00 rows=5000 width=12) (actual time=0.463..1.723 rows=5000.00 loops=2)"
" Buffers: shared hit=134"
" -> Hash (cost=1.50..1.50 rows=50 width=15) (actual time=4.508..4.509 rows=50.00 loops=2)"
" Buckets: 1024 Batches: 1 Memory Usage: 11kB"
" Buffers: shared hit=2"
" -> Seq Scan on category c (cost=0.00..1.50 rows=50 width=15) (actual time=4.441..4.453 rows=50.00 loops=2)"
" Buffers: shared hit=2"
" -> Hash (cost=1.50..1.50 rows=50 width=16) (actual time=1.980..1.982 rows=50.00 loops=2)"
" Buckets: 1024 Batches: 1 Memory Usage: 11kB"
" Buffers: shared hit=2"
" -> Seq Scan on supplier sup (cost=0.00..1.50 rows=50 width=16) (actual time=1.936..1.946 rows=50.00 loops=2)"
" Buffers: shared hit=2"
" -> Memoize (cost=0.15..0.17 rows=1 width=222) (actual time=0.001..0.001 rows=1.00 loops=137806)"
" Cache Key: s.warehouse_id"
" Cache Mode: logical"
" Hits: 137803 Misses: 3 Evictions: 0 Overflows: 0 Memory Usage: 1kB"
" Buffers: shared hit=6"
" -> Index Scan using warehouse_pkey on warehouse w (cost=0.14..0.16 rows=1 width=222) (actual time=0.026..0.026 rows=1.00 loops=3)"
" Index Cond: (warehouse_id = s.warehouse_id)"
" Index Searches: 3"
" Buffers: shared hit=6"
"Planning:"
" Buffers: shared hit=36"
"Planning Time: 3.208 ms"
"Execution Time: 7656.576 ms"
Времетраење: 7656.576 ms
3. Анализа по креирање на индексот (Со индекс)
"Incremental Sort (cost=15402.59..32868.22 rows=69037 width=321) (actual time=1631.360..4583.371 rows=54435.00 loops=1)"
" Sort Key: (to_char(date_trunc('month'::text, s.date_time), 'YYYY-MM'::text)) DESC, (sum(((si.quantity)::numeric * si.unit_price_at_sale))) DESC"
" Presorted Key: (to_char(date_trunc('month'::text, s.date_time), 'YYYY-MM'::text))"
" Full-sort Groups: 12 Sort Method: quicksort Average Memory: 30kB Peak Memory: 30kB"
" Pre-sorted Groups: 12 Sort Method: quicksort Average Memory: 568kB Peak Memory: 615kB"
" Buffers: shared hit=5013, temp read=1177 written=1180"
" -> GroupAggregate (cost=15402.25..30566.84 rows=69037 width=321) (actual time=1396.809..4486.919 rows=54435.00 loops=1)"
" Group Key: (to_char(date_trunc('month'::text, s.date_time), 'YYYY-MM'::text)), w.name, c.name, sup.name"
" Buffers: shared hit=5013, temp read=1177 written=1180"
" -> Incremental Sort (cost=15402.25..27805.36 rows=69037 width=287) (actual time=1396.785..4195.430 rows=137806.00 loops=1)"
" Sort Key: (to_char(date_trunc('month'::text, s.date_time), 'YYYY-MM'::text)) DESC, w.name, c.name, sup.name, s.sale_id"
" Presorted Key: (to_char(date_trunc('month'::text, s.date_time), 'YYYY-MM'::text))"
" Full-sort Groups: 12 Sort Method: quicksort Average Memory: 30kB Peak Memory: 30kB"
" Pre-sorted Groups: 12 Sort Method: quicksort Average Memory: 1262kB Peak Memory: 1387kB"
" Buffers: shared hit=5013, temp read=1177 written=1180"
" -> Nested Loop (cost=15402.02..25503.97 rows=69037 width=287) (actual time=1386.649..1961.612 rows=137806.00 loops=1)"
" Buffers: shared hit=5013, temp read=1177 written=1180"
" -> Gather Merge (cost=15401.87..23442.37 rows=69037 width=49) (actual time=1386.587..1595.529 rows=137806.00 loops=1)"
" Workers Planned: 2"
" Workers Launched: 2"
" Buffers: shared hit=5007, temp read=1177 written=1180"
" -> Sort (cost=14401.85..14473.76 rows=28765 width=49) (actual time=1137.373..1153.034 rows=45935.33 loops=3)"
" Sort Key: (to_char(date_trunc('month'::text, s.date_time), 'YYYY-MM'::text)) DESC"
" Sort Method: external merge Disk: 3416kB"
" Buffers: shared hit=5007, temp read=1177 written=1180"
" Worker 0: Sort Method: external merge Disk: 3080kB"
" Worker 1: Sort Method: external merge Disk: 2920kB"
" -> Hash Left Join (cost=5054.17..12271.51 rows=28765 width=49) (actual time=52.064..800.213 rows=45935.33 loops=3)"
" Hash Cond: (p.supplier_id = sup.supplier_id)"
" Buffers: shared hit=4991"
" -> Hash Left Join (cost=5052.04..12187.48 rows=28765 width=41) (actual time=51.475..514.523 rows=45935.33 loops=3)"
" Hash Cond: (p.category_id = c.category_id)"
" Buffers: shared hit=4988"
" -> Hash Join (cost=5049.92..12103.45 rows=28765 width=34) (actual time=35.759..412.608 rows=45935.33 loops=3)"
" Hash Cond: (si.product_id = p.product_id)"
" Buffers: shared hit=4985"
" -> Parallel Hash Join (cost=4870.42..11848.37 rows=28765 width=30) (actual time=19.082..351.040 rows=45935.33 loops=3)"
" Hash Cond: (si.sale_id = s.sale_id)"
" Buffers: shared hit=4784"
" -> Parallel Seq Scan on sale_item si (cost=0.00..6321.76 rows=249976 width=18) (actual time=0.010..62.241 rows=199980.67 loops=3)"
" Buffers: shared hit=3822"
" -> Parallel Hash (cost=4630.68..4630.68 rows=19179 width=16) (actual time=18.883..18.885 rows=15314.67 loops=3)"
" Buckets: 65536 Batches: 1 Memory Usage: 2688kB"
" Buffers: shared hit=962"
" -> Parallel Bitmap Heap Scan on sale s (cost=865.16..4630.68 rows=19179 width=16) (actual time=4.829..41.186 rows=45944.00 loops=1)"
" Recheck Cond: (date_time >= (date_trunc('month'::text, (CURRENT_DATE)::timestamp with time zone) - '11 mons'::interval))"
" Heap Blocks: exact=834"
" Buffers: shared hit=962"
" -> Bitmap Index Scan on idx_sale_date_time (cost=0.00..853.65 rows=46029 width=0) (actual time=4.633..4.633 rows=45944.00 loops=1)"
" Index Cond: (date_time >= (date_trunc('month'::text, (CURRENT_DATE)::timestamp with time zone) - '11 mons'::interval))"
" Index Searches: 1"
" Buffers: shared hit=128"
" -> Hash (cost=117.00..117.00 rows=5000 width=12) (actual time=16.629..16.629 rows=5000.00 loops=3)"
" Buckets: 8192 Batches: 1 Memory Usage: 279kB"
" Buffers: shared hit=201"
" -> Seq Scan on product p (cost=0.00..117.00 rows=5000 width=12) (actual time=14.267..15.406 rows=5000.00 loops=3)"
" Buffers: shared hit=201"
" -> Hash (cost=1.50..1.50 rows=50 width=15) (actual time=15.699..15.700 rows=50.00 loops=3)"
" Buckets: 1024 Batches: 1 Memory Usage: 11kB"
" Buffers: shared hit=3"
" -> Seq Scan on category c (cost=0.00..1.50 rows=50 width=15) (actual time=15.667..15.674 rows=50.00 loops=3)"
" Buffers: shared hit=3"
" -> Hash (cost=1.50..1.50 rows=50 width=16) (actual time=0.403..0.404 rows=50.00 loops=3)"
" Buckets: 1024 Batches: 1 Memory Usage: 11kB"
" Buffers: shared hit=3"
" -> Seq Scan on supplier sup (cost=0.00..1.50 rows=50 width=16) (actual time=0.374..0.381 rows=50.00 loops=3)"
" Buffers: shared hit=3"
" -> Memoize (cost=0.15..0.17 rows=1 width=222) (actual time=0.001..0.001 rows=1.00 loops=137806)"
" Cache Key: s.warehouse_id"
" Cache Mode: logical"
" Hits: 137803 Misses: 3 Evictions: 0 Overflows: 0 Memory Usage: 1kB"
" Buffers: shared hit=6"
" -> Index Scan using warehouse_pkey on warehouse w (cost=0.14..0.16 rows=1 width=222) (actual time=0.014..0.014 rows=1.00 loops=3)"
" Index Cond: (warehouse_id = s.warehouse_id)"
" Index Searches: 3"
" Buffers: shared hit=6"
"Planning:"
" Buffers: shared hit=38"
"Planning Time: 1.872 ms"
"Execution Time: 4630.112 ms"
Времетраење: 4630.112 ms
4. Дали индексот навистина се користи во планот за извршување?
Да. EXPLAIN планот по креирањето експлицитно го прикажува користењето на Bitmap Index Scan on idx_sale_date_time. Наместо да прави Seq Scan (читање на целата табела) за да ги најде соодветните датуми како претходно, системот сега директно го користи индексот за брзо лоцирање на точните блокови на податоци што одговараат на условот за последните 12 месеци.
5. Заклучок за перформансите
Времето на извршување се намали значително од ~7656 ms на ~4630 ms (намалување за скоро 40%). За разлика од првото сценарио каде немавме филтрирање, овде B-Tree индексот поставен на date_time директно ја елиминира потребата за процесирање на историските податоци (постари од една година), што резултира со огромен перформансен скок кој ќе станува све позначаен како што расте базата на податоци.
Забелешка: idx_sale_warehouse_id и idx_product_supplier_id не се
користени во планот. PostgreSQL го претпочита Seq Scan за warehouse
(3 редови) и supplier (50 редови), бидејќи за толку мали табели
Hash Join во меморијата е поевтин отколку пристап до индекс.
Овие индекси се корисни Best-Practice за Foreign Keys и ќе бидат
активирани автоматски кога табелите ќе пораснат.
Сценарио 3: Анализа на тренд на продажба и доволност на залиха
Цел: Да се анализира продажбата во последните 60 дена и врз основа на просечната дневна продажба да се пресмета дали моменталната залиха е доволна за наредните 30 дена.
WITH recent_sales AS (
SELECT
si.product_id,
SUM(si.quantity) AS sold_last_60_days
FROM sale_item si
JOIN sale s ON si.sale_id = s.sale_id
WHERE s.date_time >= CURRENT_DATE - INTERVAL '60 days'
GROUP BY si.product_id
),
current_stock AS (
SELECT
product_id,
SUM(quantity_on_hand) AS total_stock
FROM warehouse_stock
GROUP BY product_id
)
SELECT
p.product_id,
p.name AS product_name,
COALESCE(rs.sold_last_60_days, 0) AS sold_last_60_days,
ROUND(COALESCE(rs.sold_last_60_days, 0)::numeric / 60, 2) AS avg_daily_sales,
ROUND((COALESCE(rs.sold_last_60_days, 0)::numeric / 60) * 30, 2) AS projected_next_30_days,
COALESCE(cs.total_stock, 0) AS current_total_stock,
CASE
WHEN COALESCE(cs.total_stock, 0) >= ((COALESCE(rs.sold_last_60_days, 0)::numeric / 60) * 30) THEN 'SUFFICIENT'
ELSE 'INSUFFICIENT'
END AS stock_status
FROM product p
LEFT JOIN recent_sales rs ON p.product_id = rs.product_id
LEFT JOIN current_stock cs ON p.product_id = cs.product_id
ORDER BY stock_status, projected_next_30_days DESC;
1. Предложени индекси
За да се оптимизира временското пребарување и агрегацијата на залихата, предложени се следниве индекси:
CREATE INDEX idx_sale_recent_dates ON stock_management.sale(date_time DESC); CREATE INDEX idx_wh_stock_cover ON stock_management.warehouse_stock(product_id, quantity_on_hand);
2. Анализа пред креирање на индексот (Без индекс)
EXPLAIN ANALYZE
WITH recent_sales AS (
SELECT
si.product_id,
SUM(si.quantity) AS sold_last_60_days
FROM sale_item si
JOIN sale s ON si.sale_id = s.sale_id
WHERE s.date_time >= CURRENT_DATE - INTERVAL '60 days'
GROUP BY si.product_id
),
current_stock AS (
SELECT
product_id,
SUM(quantity_on_hand) AS total_stock
FROM warehouse_stock
GROUP BY product_id
)
SELECT
p.product_id,
p.name AS product_name,
COALESCE(rs.sold_last_60_days, 0) AS sold_last_60_days,
ROUND(COALESCE(rs.sold_last_60_days,0)::numeric / 60, 2) AS avg_daily_sales,
ROUND((COALESCE(rs.sold_last_60_days,0)::numeric / 60) * 30, 2) AS projected_next_30_days,
COALESCE(cs.total_stock,0) AS current_total_stock,
CASE
WHEN COALESCE(cs.total_stock,0) >=
((COALESCE(rs.sold_last_60_days,0)::numeric / 60) * 30)
THEN 'SUFFICIENT'
ELSE 'INSUFFICIENT'
END AS stock_status
FROM product p
LEFT JOIN recent_sales rs ON p.product_id = rs.product_id
LEFT JOIN current_stock cs ON p.product_id = cs.product_id
ORDER BY stock_status, projected_next_30_days DESC;
"Sort (cost=6407.95..6432.95 rows=10000 width=128) (actual time=733.443..734.040 rows=10000.00 loops=1)" " Sort Key: (CASE WHEN ((COALESCE(cs.total_stock, '0'::bigint))::numeric >= (((COALESCE(rs.sold_last_60_days, '0'::bigint))::numeric / '60'::numeric) * '30'::numeric)) THEN 'SUFFICIENT'::text ELSE 'INSUFFICIENT'::text END), (round((((COALESCE(rs.sold_last_60_days, '0'::bigint))::numeric / '60'::numeric) * '30'::numeric), 2)) DESC" " Sort Method: quicksort Memory: 1158kB" " Buffers: shared hit=1502" " -> Hash Left Join (cost=5177.04..5743.56 rows=10000 width=128) (actual time=681.340..719.364 rows=10000.00 loops=1)" " Hash Cond: (p.product_id = cs.product_id)" " Buffers: shared hit=1502" " -> Hash Left Join (cost=4638.04..4878.30 rows=10000 width=24) (actual time=652.140..661.568 rows=10000.00 loops=1)" " Hash Cond: (p.product_id = rs.product_id)" " Buffers: shared hit=1438" " -> Seq Scan on product p (cost=0.00..214.00 rows=10000 width=16) (actual time=0.116..5.126 rows=10000.00 loops=1)" " Buffers: shared hit=114" " -> Hash (cost=4638.00..4638.00 rows=3 width=12) (actual time=651.951..651.957 rows=3.00 loops=1)" " Buckets: 1024 Batches: 1 Memory Usage: 9kB" " Buffers: shared hit=1324" " -> Subquery Scan on rs (cost=4637.94..4638.00 rows=3 width=12) (actual time=651.929..651.937 rows=3.00 loops=1)" " Buffers: shared hit=1324" " -> HashAggregate (cost=4637.94..4637.97 rows=3 width=12) (actual time=651.926..651.931 rows=3.00 loops=1)" " Group Key: si.product_id" " Batches: 1 Memory Usage: 32kB" " Buffers: shared hit=1324" " -> Hash Join (cost=1490.80..4340.58 rows=59472 width=8) (actual time=220.253..612.386 rows=59442.00 loops=1)" " Hash Cond: (si.sale_id = s.sale_id)" " Buffers: shared hit=1324" " -> Seq Scan on sale_item si (cost=0.00..2456.00 rows=150000 width=12) (actual time=0.043..74.882 rows=150000.00 loops=1)" " Buffers: shared hit=956" " -> Hash (cost=1243.00..1243.00 rows=19824 width=4) (actual time=219.680..219.681 rows=19814.00 loops=1)" " Buckets: 32768 Batches: 1 Memory Usage: 953kB" " Buffers: shared hit=368" " -> Seq Scan on sale s (cost=0.00..1243.00 rows=19824 width=4) (actual time=0.074..98.152 rows=19814.00 loops=1)" " Filter: (date_time >= (CURRENT_DATE - '60 days'::interval))" " Rows Removed by Filter: 30186" " Buffers: shared hit=368" " -> Hash (cost=414.00..414.00 rows=10000 width=12) (actual time=28.495..28.497 rows=10000.00 loops=1)" " Buckets: 16384 Batches: 1 Memory Usage: 558kB" " Buffers: shared hit=64" " -> Subquery Scan on cs (cost=214.00..414.00 rows=10000 width=12) (actual time=18.392..23.647 rows=10000.00 loops=1)" " Buffers: shared hit=64" " -> HashAggregate (cost=214.00..314.00 rows=10000 width=12) (actual time=18.390..22.371 rows=10000.00 loops=1)" " Group Key: warehouse_stock.product_id" " Batches: 1 Memory Usage: 793kB" " Buffers: shared hit=64" " -> Seq Scan on warehouse_stock (cost=0.00..164.00 rows=10000 width=8) (actual time=0.345..2.190 rows=10000.00 loops=1)" " Buffers: shared hit=64" "Planning:" " Buffers: shared hit=14" "Planning Time: 21.363 ms" "Execution Time: 747.335 ms"
Времетраење: 747.335 ms
3. Анализа по креирање на индексот (Со индекс)
"Sort (cost=6257.80..6282.80 rows=10000 width=128) (actual time=188.971..189.554 rows=10000.00 loops=1)" " Sort Key: (CASE WHEN ((COALESCE(cs.total_stock, '0'::bigint))::numeric >= (((COALESCE(rs.sold_last_60_days, '0'::bigint))::numeric / '60'::numeric) * '30'::numeric)) THEN 'SUFFICIENT'::text ELSE 'INSUFFICIENT'::text END), (round((((COALESCE(rs.sold_last_60_days, '0'::bigint))::numeric / '60'::numeric) * '30'::numeric), 2)) DESC" " Sort Method: quicksort Memory: 1158kB" " Buffers: shared hit=1558" " -> Hash Left Join (cost=5026.89..5593.41 rows=10000 width=128) (actual time=125.016..182.234 rows=10000.00 loops=1)" " Hash Cond: (p.product_id = cs.product_id)" " Buffers: shared hit=1558" " -> Hash Left Join (cost=4487.89..4728.15 rows=10000 width=24) (actual time=95.217..98.959 rows=10000.00 loops=1)" " Hash Cond: (p.product_id = rs.product_id)" " Buffers: shared hit=1494" " -> Seq Scan on product p (cost=0.00..214.00 rows=10000 width=16) (actual time=0.029..1.061 rows=10000.00 loops=1)" " Buffers: shared hit=114" " -> Hash (cost=4487.85..4487.85 rows=3 width=12) (actual time=95.152..95.168 rows=3.00 loops=1)" " Buckets: 1024 Batches: 1 Memory Usage: 9kB" " Buffers: shared hit=1380" " -> Subquery Scan on rs (cost=4487.79..4487.85 rows=3 width=12) (actual time=95.135..95.141 rows=3.00 loops=1)" " Buffers: shared hit=1380" " -> HashAggregate (cost=4487.79..4487.82 rows=3 width=12) (actual time=95.133..95.138 rows=3.00 loops=1)" " Group Key: si.product_id" " Batches: 1 Memory Usage: 32kB" " Buffers: shared hit=1380" " -> Hash Join (cost=1340.65..4190.43 rows=59472 width=8) (actual time=9.461..79.811 rows=59442.00 loops=1)" " Hash Cond: (si.sale_id = s.sale_id)" " Buffers: shared hit=1380" " -> Seq Scan on sale_item si (cost=0.00..2456.00 rows=150000 width=12) (actual time=0.013..14.517 rows=150000.00 loops=1)" " Buffers: shared hit=956" " -> Hash (cost=1092.85..1092.85 rows=19824 width=4) (actual time=9.311..9.313 rows=19814.00 loops=1)" " Buckets: 32768 Batches: 1 Memory Usage: 953kB" " Buffers: shared hit=424" " -> Bitmap Heap Scan on sale s (cost=377.93..1092.85 rows=19824 width=4) (actual time=1.562..5.500 rows=19814.00 loops=1)" " Recheck Cond: (date_time >= (CURRENT_DATE - '60 days'::interval))" " Heap Blocks: exact=368" " Buffers: shared hit=424" " -> Bitmap Index Scan on idx_sale_recent_dates (cost=0.00..372.98 rows=19824 width=0) (actual time=1.478..1.478 rows=19814.00 loops=1)" " Index Cond: (date_time >= (CURRENT_DATE - '60 days'::interval))" " Index Searches: 1" " Buffers: shared hit=56" " -> Hash (cost=414.00..414.00 rows=10000 width=12) (actual time=29.688..29.691 rows=10000.00 loops=1)" " Buckets: 16384 Batches: 1 Memory Usage: 558kB" " Buffers: shared hit=64" " -> Subquery Scan on cs (cost=214.00..414.00 rows=10000 width=12) (actual time=24.584..27.744 rows=10000.00 loops=1)" " Buffers: shared hit=64" " -> HashAggregate (cost=214.00..314.00 rows=10000 width=12) (actual time=24.582..26.557 rows=10000.00 loops=1)" " Group Key: warehouse_stock.product_id" " Batches: 1 Memory Usage: 793kB" " Buffers: shared hit=64" " -> Seq Scan on warehouse_stock (cost=0.00..164.00 rows=10000 width=8) (actual time=0.028..0.841 rows=10000.00 loops=1)" " Buffers: shared hit=64" "Planning:" " Buffers: shared hit=14" "Planning Time: 0.705 ms" "Execution Time: 191.517 ms"
Времетраење: 191.517 ms
4. Дали индексот навистина се користи во планот за извршување?
Да. Од двата предложени индекси:
- idx_sale_recent_dates: ДА, искористен е. Планот експлицитно покажува Bitmap Index Scan on idx_sale_recent_dates за филтрирање на продажбите во последните 60 дена, наместо претходниот Seq Scan со Rows Removed by Filter: 30186.
- idx_wh_stock_cover: НЕ, не е искористен. CTE-то current_stock врши агрегација (SUM) на сите редови во warehouse_stock, па PostgreSQL продолжува со Seq Scan идентична ситуација со Сценарио 1.
5. Заклучок за перформансите
Времето на извршување се намали од ~747 ms на ~191 ms (подобрување од ~74%, односно ~4×). Целокупното подобрување доаѓа исклучително од idx_sale_recent_dates кој го елиминира скенирањето на историските продажби (постари од 60 дена). idx_wh_stock_cover нема ефект бидејќи агрегацијата на warehouse_stock бара читање на 100% од редовите.
Attachments (4)
- with_index_1.png (26.7 KB ) - added by 4 months ago.
- with_index_2.png (48.8 KB ) - added by 4 months ago.
- without_index_1.png (34.6 KB ) - added by 4 months ago.
- without_index_2.png (32.8 KB ) - added by 4 months ago.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Download all attachments as: .zip