Подготовка и конфигурација на модел (Proof-of-concept фаза)
Во оваа фаза на проектот сакав да демонстрирам практична употреба на моделот AudioLDM2.
Кога почнав со оваа фаза очекував да е доста "straight-forward", но набрзо се соочив со доста проблеми околу зависности и инсталација на соодветни верзии на библиотеките кои беа потребни за да го иницијализирам самиот модел. Па се навратив на читање на документациите на моделот малку подетално, и направив соодветна requirements.txt датотека кои ги содржеше сите работни и компатибилни верзии на библиотеките.
Подготовка на работна околина
1. Програмски јазик:
- Користев Python 3.10.11, бидејќи е стабилна верзија и компатибилна со библиотеките потребни за AudioLDM2.
- IDE:
- Користев
PyCharmза развој, заради подобро управување со виртуелни окружувања и дебагирање. - Направив ново
.venvво проектната папка
- GPU поддршка:
- Со команда
nvidia-smiпроверив дека имам CUDA 12.7, што е доволно ново за да работи со најнови верзии на Torch.
Инсталација на потребни библиотеки
Ги инсталирав сите неопходни пакети, водејќи сметка за компатибилни верзии. Најважни беа:
torchиtorchaudio– за GPU извршување на моделот.
diffusers– библиотеката одHuggingFaceкоја ја содржи имплементацијата на AudioLDM2.
transformers– за обработка на текстуални промптови.
accelerateиsafetensors– оптимизација на извршување и управување со тежини на моделот.
soundfile,scipy– за работа со аудио фајлови.
По првичната инсталација на audioldm2 имав повеќе грешки со зависности (кај huggingface_hub, transformers и diffusers). Со експериментирање најдов стабилна комбинација и успеав да го покренам моделот.
Конфигурација на модел
Импорт и инцијализација на модел

- Го преземав претходно обучениот модел
cvssp/audioldm2од HuggingFace.
- Моделот го префрлив на GPU со
to("cuda").
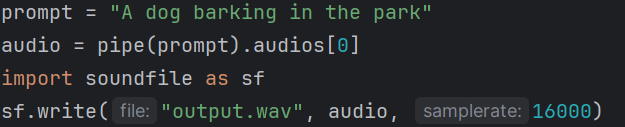
Прв тест со тескстуален промпт

- Ова ми беше првиот успешен обид после многу "troubleshooting" со верзиите и зависностите.(понатаму направив пософистицирано решение за ова со повеќе debug принтови и поефикасен импорт директно од кеш на моделот, како и намалување/оптимизирање искористеност на GPU/CPU)
Проблеми и решенија
Несовпаѓање на верзии:
huggingface_hubбеше нов и ја немаше функцијатаcached_download, тоа го решив со фиксирање на постара верзија и подоцна со надградба на Diffusers.
Недостасувачки пакети:
- На пример, добивав грешка за
soxrиClapFeatureExtractor. Ги инсталирав рачно за да продолжи моделот(така правев за многу од пакетите и библиотеките, вклучувајќи и ресетирање на виртуелна околина неколку пати).
Не-препознавање на CUDA:
- На почеток не знаев дали мојата графичка карта го поддржува CUDA и дали веќе е инсталирана. Со nvidia-smi потврдив дека системот има CUDA runtime, и после многу debug принтови успеав да го решам тоа.
Резултати од Фаза 1
- Успешно конфигурирав работна средина со
PyCharmи виртуелно окружување.
- Успешно го интегрирав AudioLDM2 и генерирав прв аудио фајл од текстуален промпт.
- Докажав дека моделот функционира локално на мојот лаптоп со GPU поддршка.
Attachments (2)
- 2.1.png (25.8 KB ) - added by 11 months ago.
- 2.2.png (22.6 KB ) - added by 11 months ago.
{kind=link}
{kind=link}
Download all attachments as: .zip