Мерење на перформанси
Перформанси со различни вредности за shared_buffers
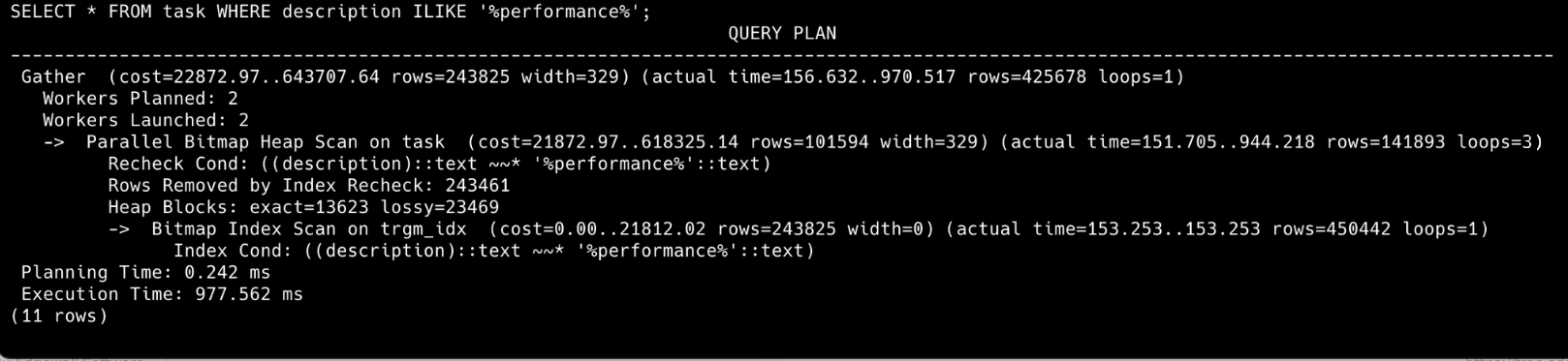
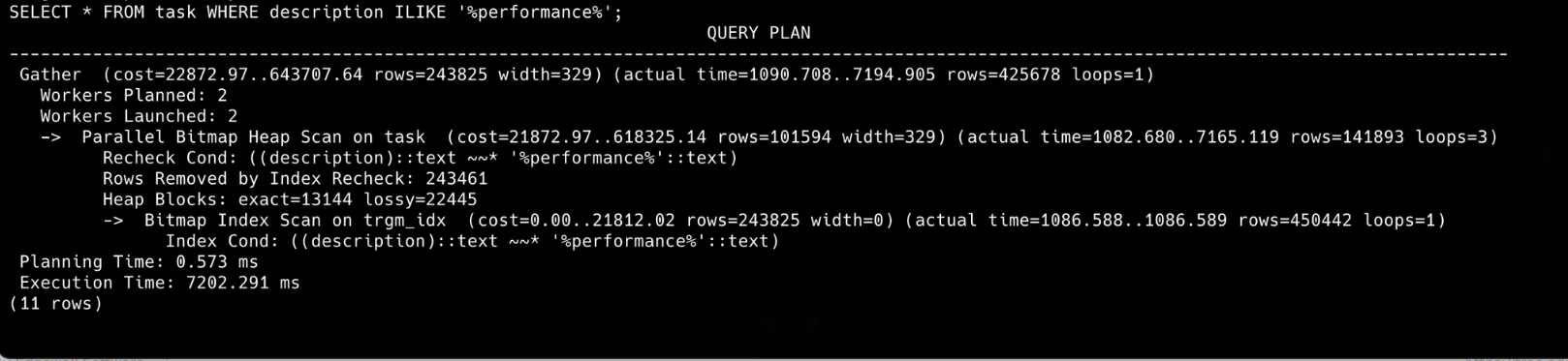
Овој тест е извршен на табелата task во која има 14.100.000 тест податоци. Тестовите се изврпени еднаш со shared_buffers: 128MB, а другиот пат со shared_buffers: 2GB.
Тест 1: select * from task where short_description ilike '%performance%';


Тест 2: select * from task where description ilike '%performance%';


Мерење на перформански на табела со партиција и без
Во овој тест се мерат перформансите на табелата test_instance во која има 37.000.000 податоци. Во едниот тест кверито е пуштено на табела без партиција, а во вториот тест истото квери е пуштено на истите податоци само што табелата е партиционирана.

Без партиција

Со партиција (еднаш наоѓа во default еднаш во конкретна партиција)

PostgreSQL Индекси
Индекси во PostgreSQL се структури на податоци што се користат за забрзување на пребарувањето во табелите. Индексите и овозможуваат на базата брзо да ги лоцира потребните редици наместо да прави sequential scan. Со користење на индекси драстично се намалува времето за select, update и delete, но поради дополнителните записи потребни за индексот се зголемува времето за insert. Индексите зафаќаат додатен простор на дискот, што некогаш може да биде и поголем од самата табела. Затоа треба внимателно да се одбере кога и каков индекс може да се користи за дадена табела.
B-tree Индекси
B-tree (Balanced Tree) индексите се засновани на структура на балансирано дрво каде што секој јазол содржи повеќе клучеви сортирани по редослед. Оваа структура автоматски се балансира, што значи дека патот од коренот до секој лист има иста должина. Кога се пребарува вредност, алгоритмот започнува од коренот и се движи надолу по дрвото, споредувајќи ги вредностите и избирајќи го следниот јазол. Ова дава логаритамска сложеност O(log n) за пребарување, вметнување и бришење. B-tree индексите автоматски се креираат за primary key и unique ограничувањата и се идеални за споредби со еднаквост и опсег (>, <, BETWEEN), како и за операции на сортирање.
GIN Индекси
GIN (Generalized Inverted Index) создава мапа од секоја вредност кон сите записи што ја содржат. Пример за JSONB колона што содржи {"tags": ["red", "blue"]}, GIN ќе создаде записи каде за "red" и "blue" кои покажуваат кон тој ред. Кога се пребарува за записи што содржат "red", индексот директно знае кои редови да ги врати. Оваа структура е многу ефикасна за операции contains (@>, <@) и full-text search, но поради начинот на којшто ги чува податоците зафаќа голем простор.
GiST Индекси
GiST (Generalized Search Tree) е структура со која може да се градат различни типови на индекси врз основа на концептот на "kлучеви-предикати". Наместо да чува точни вредности како B-tree, GiST чува информации за тоа какви податоци се содржани во секој поддел од дрвото. GiST е погоден за просторни пребарувања, nearest-neighbor пребарувања, операции со опсези на датуми и full-text search пребарување. Иако генерално е побавен од специјализираните индекси, GiST е многу помал од GIN и поефикасен за updates.
Заклучок
Избирањето на соодветен тип индекс зависи од природата на податоците и типот на пребарувања што се извршуваат. B-tree е добар за стандардни релациони операции (order by, where), GIN за брзо пребарување во сложени структури (JSONB), и GiST за флексибилни и просторни операции. Секој има свои компромиси помеѓу перформанси, големина и сложеност на одржување.
Attachments (7)
- sb_1_2.png (219.8 KB ) - added by 4 months ago.
- sb_8_5.png (128.9 KB ) - added by 4 months ago.
- sb_desc_0_9.png (212.0 KB ) - added by 4 months ago.
- sb_desc_7.png (207.2 KB ) - added by 4 months ago.
- part_1.png (131.8 KB ) - added by 4 months ago.
- part_2.png (115.3 KB ) - added by 4 months ago.
- part_3.png (134.1 KB ) - added by 4 months ago.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Download all attachments as: .zip